Deep Learning
Which Face is Real? Applying StyleGAN to Create Fake People
April 28, 2020
11 min read


A Generative model aims to learn and understand a dataset’s true distribution and create new data from it using unsupervised learning. These models (such as StyleGAN) have had mixed success as it is quite difficult to understand the complexities of certain probability distributions.
In order to sidestep these roadblocks, The Adversarial Nets Framework was created whereby the generative model is pitted against an adversary: a discriminative model that learns to determine whether a sample is from the model distribution or the data distribution.
The generative model generates samples by passing random noise through a multilayer perceptron, and the discriminative model is also a multilayer perceptron. We refer to this case as Adversarial Nets.
The paper that presents this The Adversarial Framework can be found here along with the code used for the framework.
Which Face Is Real? was developed by Jevin West and Carl Bergstrom from the University of Washington as part of the Calling Bullshit Project.
“Computers are good, but your visual processing systems are even better. If you know what to look for, you can spot these fakes at a single glance — at least for the time being. The hardware and software used to generate them will continue to improve, and it may be only a few years until humans fall behind in the arms race between forgery and detection.” – Jevin West and Carl Bergstrom

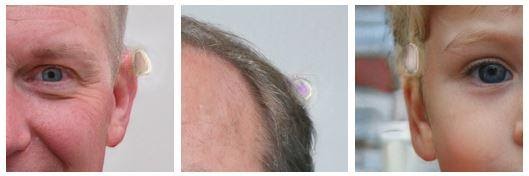
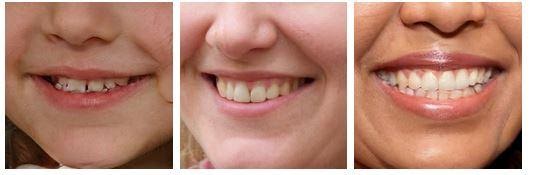
The differences are determined in 6 main areas:




All the code for the StyleGAN has been open-sourced in the stylegan repository. It gives details on how you can run the styleGAN algorithm yourself. So let’s get started with sharing some of the basic system requirements.
A minimal example to try a pre-trained example of the styleGAN is given in pretrained_example.py. It is executed as follows:
The training and evaluation scripts operate on datasets stored as multi-resolution TFRecords. Each dataset is represented by a directory containing the same image data in several resolutions to enable efficient streaming. There is a separate *.tfrecords file for each resolution, and if the dataset contains labels, they are stored in a separate file as well. By default, the scripts expect to find the datasets at datasets/<NAME>/<NAME>-<RESOLUTION>.tfrecords. The directory can be changed by editing config.py:
To obtain the FFHQ dataset (datasets/ffhq), please refer to the Flickr-Faces-HQ repository.
To obtain the CelebA-HQ dataset (datasets/celebahq), please refer to the Progressive GAN repository.
To obtain other datasets, including LSUN, please consult their corresponding project pages. The datasets can be converted to multi-resolution TFRecords using the provided dataset_tool.py:
Once the datasets are set up, you can train your own StyleGAN networks as follows:
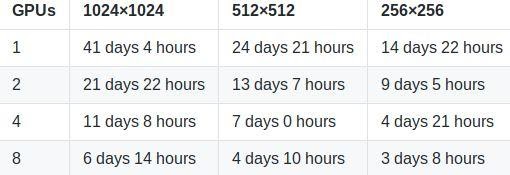
By default, train.py is configured to train the highest-quality StyleGAN (configuration F in Table 1) for the FFHQ dataset at 1024×1024 resolution using 8 GPUs.
Below you will find NVIDIA’s reported expected training times for default configuration of the train.py script (available in the stylegan repository) on a Tesla V100 GPU for the FFHQ dataset (available in the stylegan repository).

The algorithm behind this amazing app was the brainchild of Tero Karras, Samuli Laine and Timo Aila at NVIDIA and called it StyleGAN. The algorithm is based on earlier work by Ian Goodfellow and colleagues on General Adversarial Networks (GAN’s).
Generative models have a limitation in which it’s hard to control the characteristics such as facial features from photographs. NVIDIA’s StyleGAN is a fix to this limitation. The model allows the user to tune hyper-parameters that can control for the differences in the photographs.
StyleGAN solves the variability of photos by adding styles to images at each convolution layer. These styles represent different features of photos of a human, such as facial features, background color, hair, wrinkles, etc. The model generates two images A and B and then combines them by taking low-level features from A and the rest from B. At each level, different features (styles) are used to generate an image:

Have you tested out StyleGAN before? Or is this your first time? Let us know in the comment section below. We are always looking for new and creative ways from the community for any technologies or frameworks.

A Generative model aims to learn and understand a dataset’s true distribution and create new data from it using unsupervised learning. These models (such as StyleGAN) have had mixed success as it is quite difficult to understand the complexities of certain probability distributions.
In order to sidestep these roadblocks, The Adversarial Nets Framework was created whereby the generative model is pitted against an adversary: a discriminative model that learns to determine whether a sample is from the model distribution or the data distribution.
The generative model generates samples by passing random noise through a multilayer perceptron, and the discriminative model is also a multilayer perceptron. We refer to this case as Adversarial Nets.
The paper that presents this The Adversarial Framework can be found here along with the code used for the framework.
Which Face Is Real? was developed by Jevin West and Carl Bergstrom from the University of Washington as part of the Calling Bullshit Project.
“Computers are good, but your visual processing systems are even better. If you know what to look for, you can spot these fakes at a single glance — at least for the time being. The hardware and software used to generate them will continue to improve, and it may be only a few years until humans fall behind in the arms race between forgery and detection.” – Jevin West and Carl Bergstrom
The differences are determined in 6 main areas:
All the code for the StyleGAN has been open-sourced in the stylegan repository. It gives details on how you can run the styleGAN algorithm yourself. So let’s get started with sharing some of the basic system requirements.
A minimal example to try a pre-trained example of the styleGAN is given in pretrained_example.py. It is executed as follows:
The training and evaluation scripts operate on datasets stored as multi-resolution TFRecords. Each dataset is represented by a directory containing the same image data in several resolutions to enable efficient streaming. There is a separate *.tfrecords file for each resolution, and if the dataset contains labels, they are stored in a separate file as well. By default, the scripts expect to find the datasets at datasets/<NAME>/<NAME>-<RESOLUTION>.tfrecords. The directory can be changed by editing config.py:
To obtain the FFHQ dataset (datasets/ffhq), please refer to the Flickr-Faces-HQ repository.
To obtain the CelebA-HQ dataset (datasets/celebahq), please refer to the Progressive GAN repository.
To obtain other datasets, including LSUN, please consult their corresponding project pages. The datasets can be converted to multi-resolution TFRecords using the provided dataset_tool.py:
Once the datasets are set up, you can train your own StyleGAN networks as follows:
By default, train.py is configured to train the highest-quality StyleGAN (configuration F in Table 1) for the FFHQ dataset at 1024×1024 resolution using 8 GPUs.
Below you will find NVIDIA’s reported expected training times for default configuration of the train.py script (available in the stylegan repository) on a Tesla V100 GPU for the FFHQ dataset (available in the stylegan repository).
The algorithm behind this amazing app was the brainchild of Tero Karras, Samuli Laine and Timo Aila at NVIDIA and called it StyleGAN. The algorithm is based on earlier work by Ian Goodfellow and colleagues on General Adversarial Networks (GAN’s).
Generative models have a limitation in which it’s hard to control the characteristics such as facial features from photographs. NVIDIA’s StyleGAN is a fix to this limitation. The model allows the user to tune hyper-parameters that can control for the differences in the photographs.
StyleGAN solves the variability of photos by adding styles to images at each convolution layer. These styles represent different features of photos of a human, such as facial features, background color, hair, wrinkles, etc. The model generates two images A and B and then combines them by taking low-level features from A and the rest from B. At each level, different features (styles) are used to generate an image:
Have you tested out StyleGAN before? Or is this your first time? Let us know in the comment section below. We are always looking for new and creative ways from the community for any technologies or frameworks.



