Deep Learning
Reinforcement Learning: From Grid World to Self-Driving Cars
October 9, 2018
14 min read


Underlying many of the major announcements from researchers in Artificial Intelligence in the last few years is a discipline known as reinforcement learning (RL). Recent breakthroughs are mostly driven by minor twists on on classic RL ideas, enabled by the availability of powerful computing hardware and software that leverages said hardware.
To get an idea of just how hungry modern deep RL models are for compute, the following table is a non-exhaustive collection of recent RL advances and estimates of the computational resources required to accomplish each task.
| Task | Training time / wall clock time | Training results |
| Dota2 Openai Five (2018) | 900 years / 24 hours | Ongoing training since June 9th 2018 |
| Dextrous robot hand (2018) | 100 years / 50 hours | Learns real-world dexterity from 50 hrs simulated training |
| AlphaGo Zero (2017) | ~ 30 million games/ 960 hours | Beat all previous AlphaGo models |
| Dota2 1v1 (2017) | 300 years / 24 hours | Beat top players after ~ 4 months |
| AlphaGo (2016) | 4.9 million games / 72 hours | Beat world champion Lee Sedol after ~ 3 days training time |
Notice that the tasks in the table above are all trained in simulation (even the dextrous robot hand), and for the most part that's the only way the required training times are tractable. This can become particularly tricky for real-world applications like self-driving cars-more on that topic later.
As RL agents solve tasks in increasingly complex environments, they fall prey to the curse of dimensionality. This combinatorial explosion in complexity explains the need for team game-playing bots like the Dota Five to train for 900 years per day for months to beat top-tier human players, on very capable hardware. Even with ludicrous computational resources like those employed by OpenAI for Dota Five, deep RL in particular has a number of tricky sticking points that can, at best, make training very inefficient and, at worst, make many problems essentially intractable.
It's worth noting that 17 days of 900 years-per-day training after trouncing 99.5 percentile former professionals, OpenAI's Dota Five lost two matches against top professional at the 2018 International. The learning curve only gets steeper on the approach to mastery, and for RL agents this goes double. For Dota Five to advance from the 99.5 to 99.99th percentile of top players, it may take as much self-play training time as the agents have completed to date, and that to temporarily meet a moving target. For a taste of how much more difficult it is for RL agents to learn gameplay, try playing Atari games with masked priors.
Modern RL arises from the fields of optimal control and psycho-social studies of behavior, the latter largely consisting of observations of learning processes in animals. Although the animal behaviorist origins of RL go at least as far back as Alexander Bain's concept of learning via "groping and experiment" in the 1850s, perhaps a more memorable example is J.F. Skinner's eponymous Skinner boxes, aka operant conditioning chamber. These chambers provide all the principal components of an RL problem: an environment that has some sort of changing state, an agent, and an action space of potential choices the agent can take. In animal behavior a reward may be triggered by something like pressing a lever to gain a reward of food, but for RL problems in general the reward can be anything, and carefully designing a good reward function can mean the difference between an effective and a misbehaving agent.
So far we have discussed the growing number of reinforcement learning breakthroughs and the concurrent growth in demand for high performance computing to run RL models, as well as the roots of RL in animal behavior studies.
Optimal control and dynamic programming is another essential field that contributed to our modern understanding of RL. In particular, these fields gave us Bellman equations for understanding maximum reward given an environmental state (value function) and the best available action to achieve the highest potential reward from a given state (quality function).
The following image is an example of a staple example you're almost certain to see in the first lecture of any RL class.
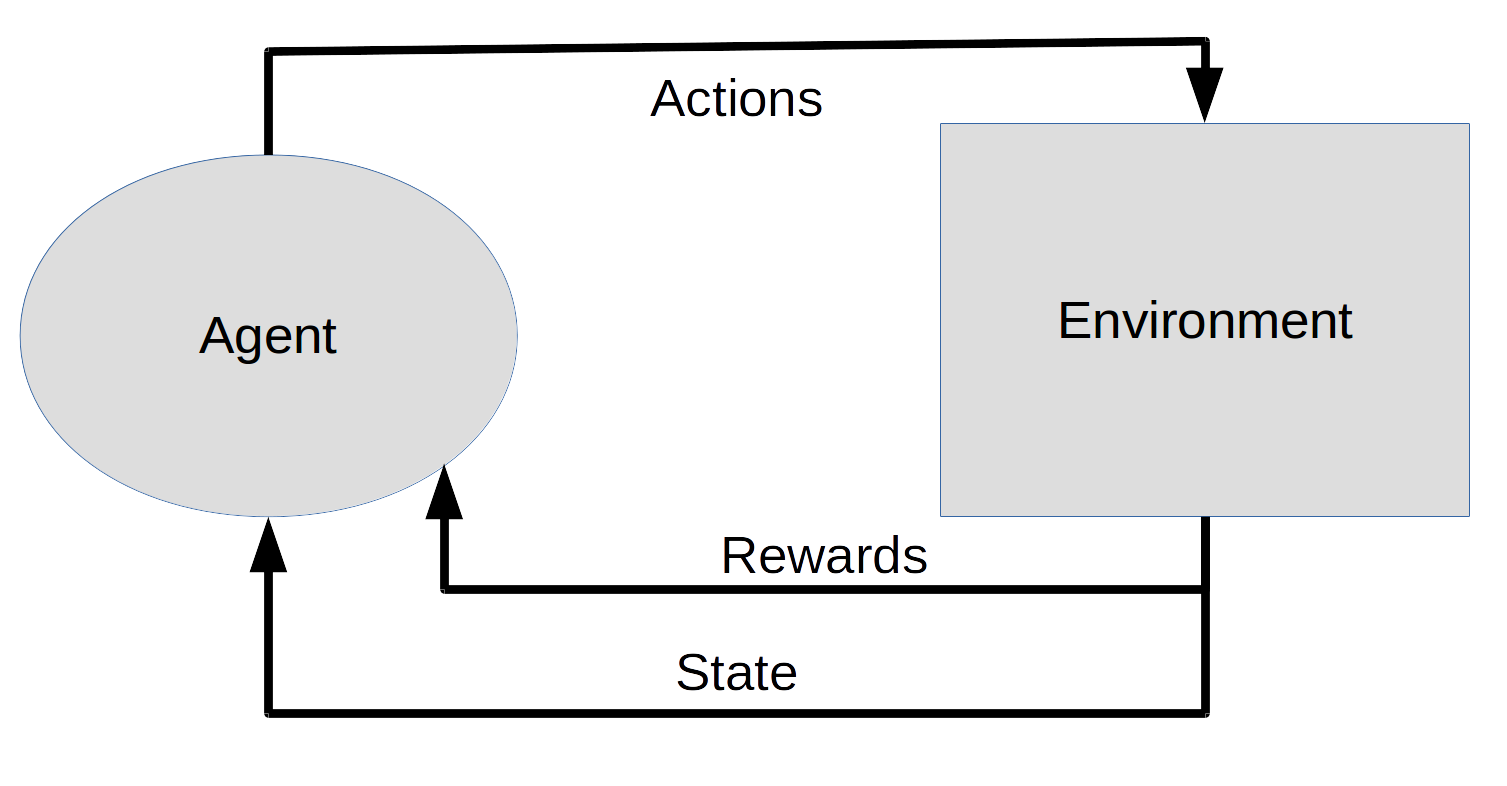
In a simplified "grid world," agents can move up, down, or side to side. Agents can't leave the grid, and certain grids may be blocked. The states in this environment are the grid locations, while a green smiley signifies a positive reward and the red box signifies a negative reward. Both positive and negative rewards are followed by exiting the game. In this example the value function (maximum potential reward for a given state) is indicated by the green saturation of each square, while the size and color of the arrows correspond to the quality function (maximum potential reward for an action taken in a given state). Because the agent discounts future rewards in favor of immediate rewards, value and quality functions are diminished for states which require more moves to reach a goal.
In a simple example like grid world, value and quality functions can effectively be stored in a look-up table to ensure an agent always makes the optimal decision in a given environment. For more realistic scenarios, these functions are not known beforehand and the environment must be explored to generate an estimate of the quality function, after which an agent can greedily seek to maximize reward by exploiting its understanding of the environment and its rewards. One effective way to explore and exploit an RL environment is to use a deep neural network to estimate the quality function.
In a seminal 2013 paper, researchers from Deepmind published a general reinforcement learner that was able to meet or exceed human-level performance in 29 of 49 classic Atari video games. The key achievement of the paper was, unlike simpler reinforcement learning problems which may have special access to game mechanics information, the model demonstrated in the paper used only the pixels of the game as input, much like a human player would. Additionally the same model was able to learn a diverse range of different types of games, from Boxing to Sea Quest. This approach, where inputs are read by a neural network on one end and desired behaviors are directly learned, without hand-coded modules gluing different aspects of the agent together, is called end-to-end deep learning. In the case of Deepmind's DQN model, the input was the last few frames of a video game and the output was the quality function, a description of the agent's expectation of rewards for different actions.
Fast forward a few years, and state-of-the-art deep reinforcement learning agents have become even simpler. Instead of learning to predict the anticipated rewards for each action, policy gradient agents train to directly choose an action given a current environmental state. This is accomplished in essence by turning a reinforcement learning problem into a supervised learning problem:
The efficacy of increasing the probability of every action (including mistakes) for a run that eventually yielded a positive reward may seem surprising, but in practice and averaged over many runs, winning performances will include more correct actions and lower reward performances will include more mistakes. This is the simple basis for RL agents that learn parkour-style locomotion, robotic soccer skills, and yes, autonomous driving with end-to-end deep learning using policy gradients. A video from Wayve demonstrates an RL agent learning to drive a physical car on an isolated country road in about 20 minutes, with distance travelled between human operator interventions as the reward signal.
That's a pretty compelling demo, albeit a very simplified one. Remember the curse of dimensionality mentioned earlier? Real-world driving has many more variables than single country lanes. For RL, each new aspect can be expected to entail exponentially greater training requirements. Given the current state of the art, it's inevitable that fully autonomous cars will require soem degree of learning in simulated environments, extensive hand-coded modules to tie together functionalities and handle edge-cases, or both.
One of the most visible applications promised by the modern resurgence in machine learning is self-driving cars. Automobiles are probably the most dangerous modern technology to be accepted and taken in stride as an everyday necessity, with annual road traffic deaths estimated at 1.25 million worldwide by the World Health Organization. According to Autovolo.co.uk, "More than half of all road deaths are amongst vulnerable road users - cyclists, pedestrians and motorcyclists." Pinning down the economic impacts of autonomous vehicles is difficult, but conservative estimates range from $190 to $642 billion per year in the US alone.
Modern autonomous driving has origins in projects like ALVINN controlling the Carnegie Mellon autonomous driving testbed NAVLAB and Ernst Dickmann's work at Bundeswehr University in the 1980s and 1990s. Many of the components of those projects might seem familiar to modern self-driving developers: ALVINN utilized a neural network to predict turn curvature from a 30x32 video feed and laser rangefinder inputs. To get around computing bottlenecks, Dickmann's dynamic vision system focused computation on predefined areas of images based on expected importance, a concept very similar to neural attention in modern networks.
Many of the innovations coming out of the self-driving cars of the 1980s and 1990s were necessary to overcome bottlenecks in data throughput or processing. More recently, that availability of computing power is no longer the bottleneck and the main challenges to overcoming the last 10% or so of challenges for full automobile autonomy are related to ensuring training data reliability and handling unusual edge cases effectively.
The success of neural networks in computer vision tasks makes those an obvious job for deep learning, and a typical engineering approach might combine deep learning for vision with other learned or hard-coded modules to handle all aspects of driving. Increasingly, instead of designing and training separate individual models that must be coerced to work together by many talented engineers, autonomous driving developers are relying on clever models with high-quality training data and carefully thought out objective functions to learn a more comprehensive set of skills for driving. If we imagine the state of the self-driving technology stack and the direction the field is going, it might look something like the following block diagram.
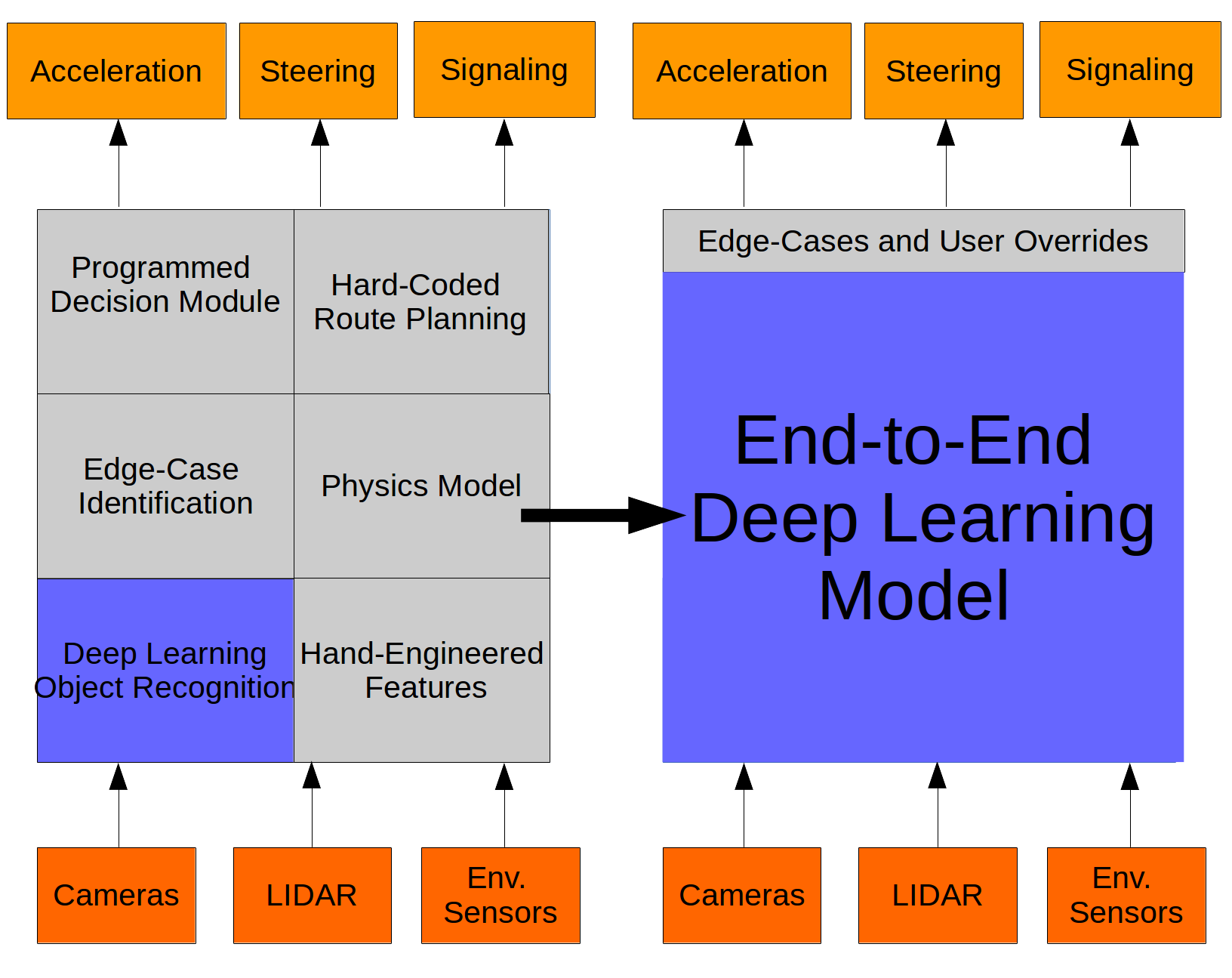
The self-driving cars of a few decades ago were ahead of their time, constrained by computational limitations on processing time and data throughput. The major differentiator between then and now is the availability of powerful computational resources. Many researchers point to the stunning performance in the ImageNet Large Scale Visual Recognition Challenge by a convolutional neural network trained on a Graphics Processing Unit (GPU) in 2012 as the spark that ignited the modern resurgence in machine learning, characterized by training big models on big datasets and leveraging the parallel processing power of GPUs. This has fed into a virtuous cycle attracting additional interest and funding, leading to further accomplishments and wider utility domains, and ultimately driving further innovation with new twists on old ideas. There are still plenty of challenges to overcome to achieve fully autonomous vehicles we can trust, and there are sure to be many more exciting and unknown opportunities to solve interesting problems as computational resources continue to improve.
Given the consequences of the combinatorial explosion of messy real-world conditions and the high stakes involved, RL may need fundamental breakthroughs to make fully autonomous driving a reality. Learning how to handle unseen edge-cases, or training high-level imperatives like "the fundamental rule of the road is to get around while causing no harm," are not things that RL does well. Focusing on correctly identifying a worn or mispainted lane marking, for example, is far less important than teaching a driving agent to anticipate and avoid a cyclist dodging out of the bike lane to avoid a pothole. The learning curve from lane-keeping and identifying obvious and known obstacles to zero-intervention driving is steep, and climbing it properly is the difference between reaping the rewards of technologies like fully autonomous vehicles and catastrophic consequences that postpone that future, perhaps indefinitely.
Underlying many of the major announcements from researchers in Artificial Intelligence in the last few years is a discipline known as reinforcement learning (RL). Recent breakthroughs are mostly driven by minor twists on on classic RL ideas, enabled by the availability of powerful computing hardware and software that leverages said hardware.
To get an idea of just how hungry modern deep RL models are for compute, the following table is a non-exhaustive collection of recent RL advances and estimates of the computational resources required to accomplish each task.
| Task | Training time / wall clock time | Training results |
| Dota2 Openai Five (2018) | 900 years / 24 hours | Ongoing training since June 9th 2018 |
| Dextrous robot hand (2018) | 100 years / 50 hours | Learns real-world dexterity from 50 hrs simulated training |
| AlphaGo Zero (2017) | ~ 30 million games/ 960 hours | Beat all previous AlphaGo models |
| Dota2 1v1 (2017) | 300 years / 24 hours | Beat top players after ~ 4 months |
| AlphaGo (2016) | 4.9 million games / 72 hours | Beat world champion Lee Sedol after ~ 3 days training time |
Notice that the tasks in the table above are all trained in simulation (even the dextrous robot hand), and for the most part that's the only way the required training times are tractable. This can become particularly tricky for real-world applications like self-driving cars-more on that topic later.
As RL agents solve tasks in increasingly complex environments, they fall prey to the curse of dimensionality. This combinatorial explosion in complexity explains the need for team game-playing bots like the Dota Five to train for 900 years per day for months to beat top-tier human players, on very capable hardware. Even with ludicrous computational resources like those employed by OpenAI for Dota Five, deep RL in particular has a number of tricky sticking points that can, at best, make training very inefficient and, at worst, make many problems essentially intractable.
It's worth noting that 17 days of 900 years-per-day training after trouncing 99.5 percentile former professionals, OpenAI's Dota Five lost two matches against top professional at the 2018 International. The learning curve only gets steeper on the approach to mastery, and for RL agents this goes double. For Dota Five to advance from the 99.5 to 99.99th percentile of top players, it may take as much self-play training time as the agents have completed to date, and that to temporarily meet a moving target. For a taste of how much more difficult it is for RL agents to learn gameplay, try playing Atari games with masked priors.
Modern RL arises from the fields of optimal control and psycho-social studies of behavior, the latter largely consisting of observations of learning processes in animals. Although the animal behaviorist origins of RL go at least as far back as Alexander Bain's concept of learning via "groping and experiment" in the 1850s, perhaps a more memorable example is J.F. Skinner's eponymous Skinner boxes, aka operant conditioning chamber. These chambers provide all the principal components of an RL problem: an environment that has some sort of changing state, an agent, and an action space of potential choices the agent can take. In animal behavior a reward may be triggered by something like pressing a lever to gain a reward of food, but for RL problems in general the reward can be anything, and carefully designing a good reward function can mean the difference between an effective and a misbehaving agent.
So far we have discussed the growing number of reinforcement learning breakthroughs and the concurrent growth in demand for high performance computing to run RL models, as well as the roots of RL in animal behavior studies.
Optimal control and dynamic programming is another essential field that contributed to our modern understanding of RL. In particular, these fields gave us Bellman equations for understanding maximum reward given an environmental state (value function) and the best available action to achieve the highest potential reward from a given state (quality function).
The following image is an example of a staple example you're almost certain to see in the first lecture of any RL class.
In a simplified "grid world," agents can move up, down, or side to side. Agents can't leave the grid, and certain grids may be blocked. The states in this environment are the grid locations, while a green smiley signifies a positive reward and the red box signifies a negative reward. Both positive and negative rewards are followed by exiting the game. In this example the value function (maximum potential reward for a given state) is indicated by the green saturation of each square, while the size and color of the arrows correspond to the quality function (maximum potential reward for an action taken in a given state). Because the agent discounts future rewards in favor of immediate rewards, value and quality functions are diminished for states which require more moves to reach a goal.
In a simple example like grid world, value and quality functions can effectively be stored in a look-up table to ensure an agent always makes the optimal decision in a given environment. For more realistic scenarios, these functions are not known beforehand and the environment must be explored to generate an estimate of the quality function, after which an agent can greedily seek to maximize reward by exploiting its understanding of the environment and its rewards. One effective way to explore and exploit an RL environment is to use a deep neural network to estimate the quality function.
In a seminal 2013 paper, researchers from Deepmind published a general reinforcement learner that was able to meet or exceed human-level performance in 29 of 49 classic Atari video games. The key achievement of the paper was, unlike simpler reinforcement learning problems which may have special access to game mechanics information, the model demonstrated in the paper used only the pixels of the game as input, much like a human player would. Additionally the same model was able to learn a diverse range of different types of games, from Boxing to Sea Quest. This approach, where inputs are read by a neural network on one end and desired behaviors are directly learned, without hand-coded modules gluing different aspects of the agent together, is called end-to-end deep learning. In the case of Deepmind's DQN model, the input was the last few frames of a video game and the output was the quality function, a description of the agent's expectation of rewards for different actions.
Fast forward a few years, and state-of-the-art deep reinforcement learning agents have become even simpler. Instead of learning to predict the anticipated rewards for each action, policy gradient agents train to directly choose an action given a current environmental state. This is accomplished in essence by turning a reinforcement learning problem into a supervised learning problem:
The efficacy of increasing the probability of every action (including mistakes) for a run that eventually yielded a positive reward may seem surprising, but in practice and averaged over many runs, winning performances will include more correct actions and lower reward performances will include more mistakes. This is the simple basis for RL agents that learn parkour-style locomotion, robotic soccer skills, and yes, autonomous driving with end-to-end deep learning using policy gradients. A video from Wayve demonstrates an RL agent learning to drive a physical car on an isolated country road in about 20 minutes, with distance travelled between human operator interventions as the reward signal.
That's a pretty compelling demo, albeit a very simplified one. Remember the curse of dimensionality mentioned earlier? Real-world driving has many more variables than single country lanes. For RL, each new aspect can be expected to entail exponentially greater training requirements. Given the current state of the art, it's inevitable that fully autonomous cars will require soem degree of learning in simulated environments, extensive hand-coded modules to tie together functionalities and handle edge-cases, or both.
One of the most visible applications promised by the modern resurgence in machine learning is self-driving cars. Automobiles are probably the most dangerous modern technology to be accepted and taken in stride as an everyday necessity, with annual road traffic deaths estimated at 1.25 million worldwide by the World Health Organization. According to Autovolo.co.uk, "More than half of all road deaths are amongst vulnerable road users - cyclists, pedestrians and motorcyclists." Pinning down the economic impacts of autonomous vehicles is difficult, but conservative estimates range from $190 to $642 billion per year in the US alone.
Modern autonomous driving has origins in projects like ALVINN controlling the Carnegie Mellon autonomous driving testbed NAVLAB and Ernst Dickmann's work at Bundeswehr University in the 1980s and 1990s. Many of the components of those projects might seem familiar to modern self-driving developers: ALVINN utilized a neural network to predict turn curvature from a 30x32 video feed and laser rangefinder inputs. To get around computing bottlenecks, Dickmann's dynamic vision system focused computation on predefined areas of images based on expected importance, a concept very similar to neural attention in modern networks.
Many of the innovations coming out of the self-driving cars of the 1980s and 1990s were necessary to overcome bottlenecks in data throughput or processing. More recently, that availability of computing power is no longer the bottleneck and the main challenges to overcoming the last 10% or so of challenges for full automobile autonomy are related to ensuring training data reliability and handling unusual edge cases effectively.
The success of neural networks in computer vision tasks makes those an obvious job for deep learning, and a typical engineering approach might combine deep learning for vision with other learned or hard-coded modules to handle all aspects of driving. Increasingly, instead of designing and training separate individual models that must be coerced to work together by many talented engineers, autonomous driving developers are relying on clever models with high-quality training data and carefully thought out objective functions to learn a more comprehensive set of skills for driving. If we imagine the state of the self-driving technology stack and the direction the field is going, it might look something like the following block diagram.
The self-driving cars of a few decades ago were ahead of their time, constrained by computational limitations on processing time and data throughput. The major differentiator between then and now is the availability of powerful computational resources. Many researchers point to the stunning performance in the ImageNet Large Scale Visual Recognition Challenge by a convolutional neural network trained on a Graphics Processing Unit (GPU) in 2012 as the spark that ignited the modern resurgence in machine learning, characterized by training big models on big datasets and leveraging the parallel processing power of GPUs. This has fed into a virtuous cycle attracting additional interest and funding, leading to further accomplishments and wider utility domains, and ultimately driving further innovation with new twists on old ideas. There are still plenty of challenges to overcome to achieve fully autonomous vehicles we can trust, and there are sure to be many more exciting and unknown opportunities to solve interesting problems as computational resources continue to improve.
Given the consequences of the combinatorial explosion of messy real-world conditions and the high stakes involved, RL may need fundamental breakthroughs to make fully autonomous driving a reality. Learning how to handle unseen edge-cases, or training high-level imperatives like "the fundamental rule of the road is to get around while causing no harm," are not things that RL does well. Focusing on correctly identifying a worn or mispainted lane marking, for example, is far less important than teaching a driving agent to anticipate and avoid a cyclist dodging out of the bike lane to avoid a pothole. The learning curve from lane-keeping and identifying obvious and known obstacles to zero-intervention driving is steep, and climbing it properly is the difference between reaping the rewards of technologies like fully autonomous vehicles and catastrophic consequences that postpone that future, perhaps indefinitely.



