HPC
Examining HPC Storage Performance on Deep Learning Workloads with BeeGFS Parallel File System
September 17, 2019
5 min read


Deep learning applications require specific features to fully utilize HPC clusters. Data inputs typically consist of batched inputs of small random files which in turn require a parallel file system to have applicable features for deep learning. Recently, BeeGFS HPC storage has turned many heads in the research community for its performance, scalability, ease of use, and costs. Furthermore, features such as BeeOND and Tiered Storage Pools enhance user experience for deep learning on large HPC installations. BeeGFS also supports multiple metadata servers for managing metadata in a per-file or per-directory basis. In this blog, we look at some recent implementations, mainly a recent study[1] of BeeGFS on TensorFlow and analyze the results.
When conducting training on HPC clusters, parallel file systems are commonly used for storing large structural volumes. Deep learning frameworks, such as TensorFlow call read requests to the file system and form mini-batches of training data. These highly random small file accesses are in direct contrast to many of the traditional well-structured HPC I/O patterns of traditional HPC.
This random file access using the Stochastic Gradient Descent (SGD) model optimizer is a popular method. The SGD model optimizer requires mini-batches being iteratively trained in a randomized order. This is important for accelerating the model’s convergence speed. Standard parallel filesystems which are typically designed and optimized for large sequential I/O come under significant pressure in this case.
To get the best deep learning performance out of large HPC installations, TensorFlow offers built-in input pipelines I/O parallelism. However, popular image datasets such as ImageNet often have millions of relatively small images each ranging from 100 KB to 200 KB. Let's see how BeeGFS performs.

To analyze the behavior of I/O during deep learning training, Chowdhuy et al, considered two convolutional neural network (CNN) models AlexNet and ResNet-50 running on top of LBANN (Livermore Big Artificial Neural Network Toolkit). They ran experiments using a distributed ImageNet input data pipeline developed using TensorFlow and Horovod.
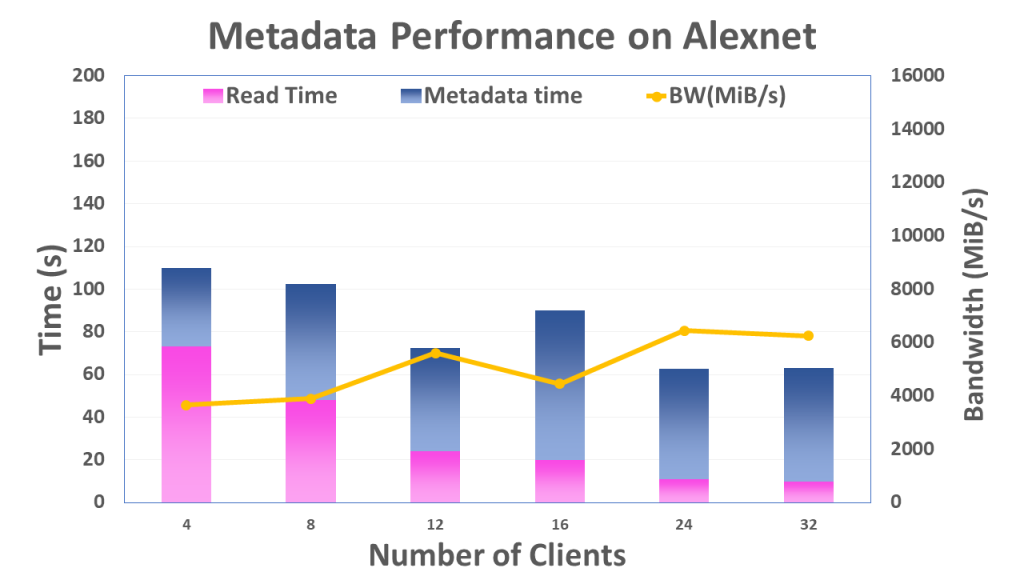

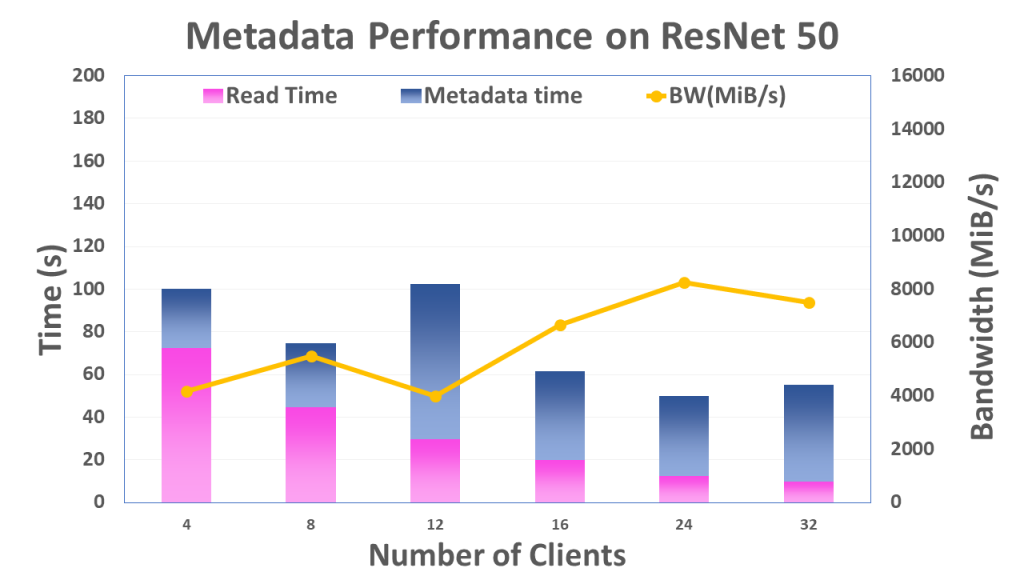
Tests were performed using the ImageNet dataset kept on a BeeGFS mount point in the cluster. The stripe size of 512 KB and stripe count of 4 for the dataset was used. In the experiments, they increased the number of nodes involved in running the models from 4 to 32 while keeping the number of processes per node fixed at 8. They then collected the average cumulative time per process for file read and metadata operations, and the average data read by each process from Darshan traces. Finally, they deduce the total data read and divide it with the total I/O time, i.e., read time + metadata time, to estimate the parallel I/O bandwidth.
Even though data pipelines in DL frameworks can put tremendous pressure on on the filesystem, BeeGFS reasonably handles the I/O access patterns posed by the DL application benchmarks.
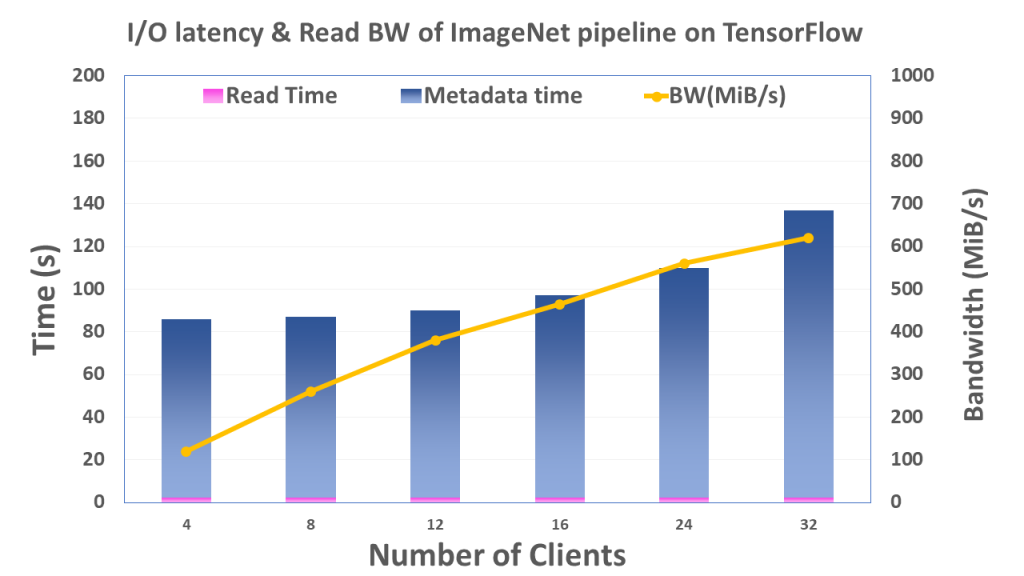
Metadata handling is and has been a notable bottleneck in TensorFlow data pipeline on HPC systems. The internal file read optimization in TensorFlow helps lessen the average read time, however the metadata overhead remains high. While TensorFlow optimizes file read time by lessening the read access size, the metadata overhead still remains the same, because the files are required to be opened anyway. Hence, metadata handling stays as the main bottleneck in the data import pipeline, and research is currently working to optimize this further. Parallel File Systems with exceptional metadata handling such as BeeGFS are perhaps the best option for TensorFlow on HPC.
[1] I/O Characterization and Performance Evaluation of BeeGFS for Deep Learning, Choudhury et al. ICPP 2019 Proceedings of the 48th International Conference on Parallel Processing
Article No. 80

Deep learning applications require specific features to fully utilize HPC clusters. Data inputs typically consist of batched inputs of small random files which in turn require a parallel file system to have applicable features for deep learning. Recently, BeeGFS HPC storage has turned many heads in the research community for its performance, scalability, ease of use, and costs. Furthermore, features such as BeeOND and Tiered Storage Pools enhance user experience for deep learning on large HPC installations. BeeGFS also supports multiple metadata servers for managing metadata in a per-file or per-directory basis. In this blog, we look at some recent implementations, mainly a recent study[1] of BeeGFS on TensorFlow and analyze the results.
When conducting training on HPC clusters, parallel file systems are commonly used for storing large structural volumes. Deep learning frameworks, such as TensorFlow call read requests to the file system and form mini-batches of training data. These highly random small file accesses are in direct contrast to many of the traditional well-structured HPC I/O patterns of traditional HPC.
This random file access using the Stochastic Gradient Descent (SGD) model optimizer is a popular method. The SGD model optimizer requires mini-batches being iteratively trained in a randomized order. This is important for accelerating the model’s convergence speed. Standard parallel filesystems which are typically designed and optimized for large sequential I/O come under significant pressure in this case.
To get the best deep learning performance out of large HPC installations, TensorFlow offers built-in input pipelines I/O parallelism. However, popular image datasets such as ImageNet often have millions of relatively small images each ranging from 100 KB to 200 KB. Let's see how BeeGFS performs.
To analyze the behavior of I/O during deep learning training, Chowdhuy et al, considered two convolutional neural network (CNN) models AlexNet and ResNet-50 running on top of LBANN (Livermore Big Artificial Neural Network Toolkit). They ran experiments using a distributed ImageNet input data pipeline developed using TensorFlow and Horovod.
Tests were performed using the ImageNet dataset kept on a BeeGFS mount point in the cluster. The stripe size of 512 KB and stripe count of 4 for the dataset was used. In the experiments, they increased the number of nodes involved in running the models from 4 to 32 while keeping the number of processes per node fixed at 8. They then collected the average cumulative time per process for file read and metadata operations, and the average data read by each process from Darshan traces. Finally, they deduce the total data read and divide it with the total I/O time, i.e., read time + metadata time, to estimate the parallel I/O bandwidth.
Even though data pipelines in DL frameworks can put tremendous pressure on on the filesystem, BeeGFS reasonably handles the I/O access patterns posed by the DL application benchmarks.
Metadata handling is and has been a notable bottleneck in TensorFlow data pipeline on HPC systems. The internal file read optimization in TensorFlow helps lessen the average read time, however the metadata overhead remains high. While TensorFlow optimizes file read time by lessening the read access size, the metadata overhead still remains the same, because the files are required to be opened anyway. Hence, metadata handling stays as the main bottleneck in the data import pipeline, and research is currently working to optimize this further. Parallel File Systems with exceptional metadata handling such as BeeGFS are perhaps the best option for TensorFlow on HPC.
[1] I/O Characterization and Performance Evaluation of BeeGFS for Deep Learning, Choudhury et al. ICPP 2019 Proceedings of the 48th International Conference on Parallel Processing
Article No. 80



