Deep Learning
Deepminds Gaming Streak: The Rise of AI Dominance
May 5, 2020
23 min read


Humans have played board games at least since the ancient Egyptian game of Senet, with game pieces found in burials dating back to 3500 BC (although the precursors of Backgammon may be older). Playing in general is an essential part of learning for animals, including humans. Deepmind has proven games are also a fertile substrate for developing machine learning and artificial intelligence.
Games, especially classic board games like chess and Go (Go is generally capitalized in English to differentiate from the verb) make good candidates for developing machine game players thanks to a few shared characteristics. Games where self-play is possible are especially ripe candidates for developing capable agents as an agent experiences an environment with an adaptive difficulty provided by an improving opponent.
Games also tend to have a definite outcome (win, draw, or lose), are deterministic in their actions, and have no hidden information. This simplifies the learning process substantially compared to real world scenarios that incorporate uncertainty from unknowns, stochastic processes, and ambiguous outcomes. Correspondingly chess, go, and classic video games make good toy problems for AI development, albeit toy problems with more possible game states than there are atoms in the universe.
Eventually the characteristics that make board games good subjects for developing AI become a hindrance. Imperfect information and long time horizons are an intrinsic part of the world we live in, and if researchers want to develop a general intelligence capable of dealing with it they need to find harder games. Modern video games provide such a venue, with fog-of-war uncertainty and very long time horizons to complicate an already complex state space.
Several of the largest artificial intelligence research institutions have teams devoted to real-time-strategy video games: Deepmind has focused on Starcraft II while OpenAI has focused their energies on developing Dota 2. These efforts represent the pinnacle of game-playing machines, although there are nascent efforts to teach machines to play open-ended, creative games like Microsoft’s Malmö project built on top of Minecraft.

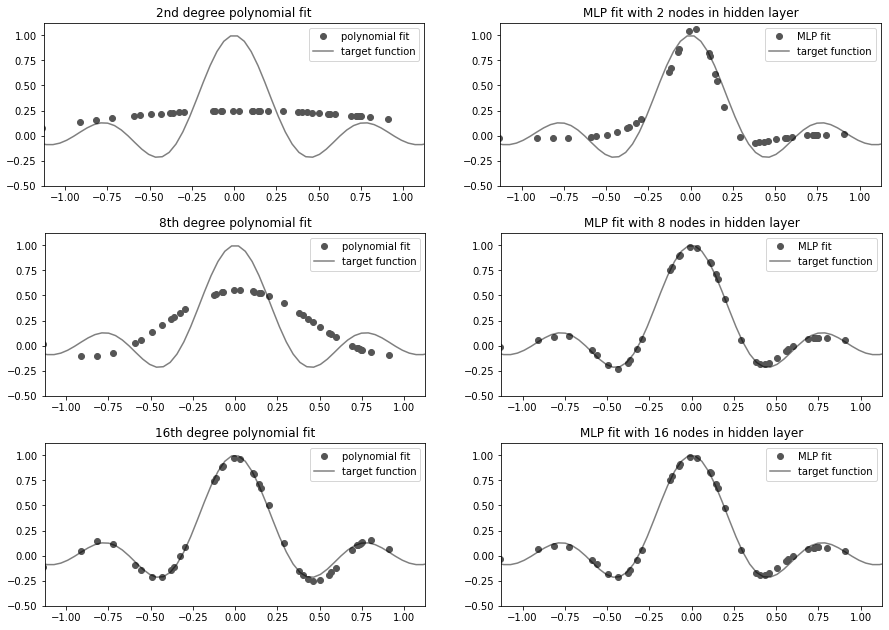
Under the Universal Approximation Theorem (UAT), a neural network with a single hidden layer and a non-linear activation function is capable of approximating any function with a finite (but sometimes quite large) number of activation nodes in the hidden layer. This is conceptually similar to performing Fourier decomposition of a signal or polynomial fits, shown here. The more Fourier bases, higher polynomial degree, or number of activation nodes in the hidden layer, the better a function can be approximated.
The trick that differentiates modern efforts in machine gaming from game playing accomplishments of the 1990s like IBM’s Deep Blue chess playing computer and the University of Alberta’s Chinook checkers playing program is the liberal application of deep neural networks. This is a useful thing to do thanks to a theorem described in the late 1980s/early 1990s by Cybenko and Hornik called the Universal Approximation Theorem (UAT). Under the UAT, even a single-hidden layer feed-forward neural network with a non-linear activation function can approximate any arbitrary function.
Universal approximation with neural networks is a little like polynomial fitting. Where a polynomial fit stores the input/output relation in a series of coefficients, a neural network represents the transformation in network weights. In both cases increasing the number of activation nodes (or the degree of the polynomial) makes for a better representation.
Under the original formulation of the UAT, based on shallow networks, the width of the network can grow exponentially. Much of the deep learning revolution in machine learning over the past decade has come from the appreciation that depth is empirically much more useful than width in neural networks, and indeed the UAT has been updated by Zhou Lu and colleagues to reflect this finding theoretically.
Bringing it all together, deep neural networks can be used to approximate any continuous function. What’s more, they can be coaxed to do a reasonably good job at generalizing to unseen data, so long as the network is trained on a sufficiently large number of training samples. So we can describe the role of neural networks in reinforcement learning as high-dimensional function approximators.
Unlike image classification, which only has one place to apply a deep neural network (the transformation from input images to class labels), in deep reinforcement learning there are many different functions to approximate including value functions, action-value functions, and input-action pairings. In practice these networks tend to be small, with as little as a single hidden layer of less than 32 activations.
In fact simple tasks like balancing a rod on a rail can be accomplished with no more than 7 binary connections in a single hidden layer feed-forward network. The networks used for basic RL experiments may seem paltry next to the 100+ layers used in state-of-the-art image tasks, but this is starting to change with the rise of procedurally-generated environments (which discourage overfitting) and more challenging tasks.
You might actually say that the history of game-playing at Deepmind actually predates the formation of the company itself. Demis Hassabis, the CEO and co-founder of Deepmind, has a long-standing obsession with gaming that predates the Deepmind’s victories over top players in Go and Starcraft II, before Google acquired the company for about £400/$660 million GBP/USD in 2014, and even before the company was founded in 2010. Demis Hassabis started his career making video games.
In fact, he was building games for Bullfrog Productions before he went on to study computer science at Cambridge University in England. After graduating he worked on games such as Black & White at Lionhead Studios before going back to university for a PhD in neuroscience and finally founding Deepmind in 2010 with Shane Legg and Mustafa Suleyman. It would be 6 years before Deepmind shocked the world with a victory over the reigning world (human) champion of Go, Lee Sedol (https://en.wikipedia.org/wiki/Lee_Sedol). The Go project eventually culminated (so far) in more general game playing models AlphaZero and MuZero, but before diving into the lineage of Deepmind’s Go champion let’s take a little detour to the arcade.
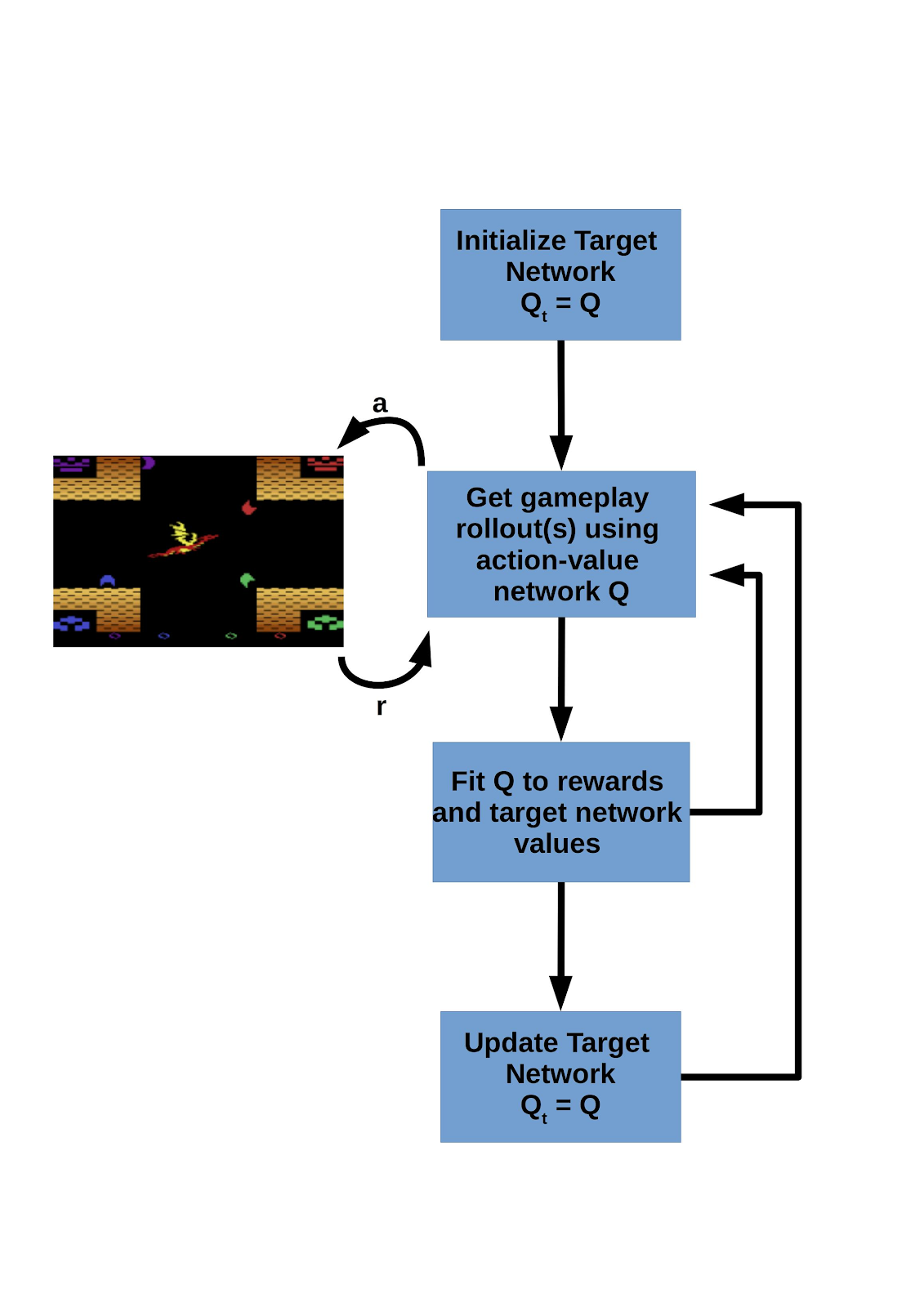
DQN in a nutshell: The DQN algorithm works by gathering game play rollouts using an action-value policy. Game transitions are sampled from the rollout buffer, which includes episodes from multiple training epochs. The action-value network, Q, is updated at each training episode to match the rewards output by the environment and the values estimated by Qt , the action-value target network. Screenshot from a homebrew Atari game is in the public domain
Deepmind’s initial foray into learning classic Atari 2600 games, spearheaded by Volodymyr Mnih, learned to play seven games, achieving average human level performance on three of the seven. That was 2013, three years after the founding of the company. In 2015 they expanded the battery of games to a comprehensive Atari suite of 49 games, matching or beating the performance of a professional human games tester on 23 of them.
That may sound a bit disappointing, but the DQN algorithm game-learner utilized the same network architecture and hyperparameters to learn each game. Despite impressive performance within 25% of human ability on the majority of games, a few Atari games remain “RL-hard.” These are extremely difficult for a machine to learn. Most of these games rely heavily on exploration, and include the infamous Montezuma’s revenge as well as Gravitar and Private Eye.
In the span of two years of development time between the initial publication of the DQN Atari learner and the human-level performance paper, the team at Deepmind improved the stability of training by incorporating experience replay and a second target function with an occasional, periodic update schedule.
These changes led to impressive performance, including the famous Breakout solution. After several hundred training updates the agent learns an optimal strategy: tunnel through the edge blocks and serve the ball behind the wall to take out many bricks at once.
The DQN paper on Atari is a notable example of end-to-end deep learning. The inputs are images generated by the game emulator, and the outputs are actions corresponding to pressing a specific button or buttons on the Atari console. That this work was going on at Deepmind probably played no small part in Google’s decision to buy the company in 2014.
But Atari games are all very similar, and though they can be difficult to master for humans and machines alike, they were never considered to be a lofty intellectual pursuit like Chess. To cement their status in game-playing history alongside the likes of Deep Blue vs. Kasparov, Deepmind would need to take on the noble game of Go.

Before beginning a precocious career as a video game developer Demis Hassabis was a keen chess player, achieving the rank of master with an Elo rating of 2300 at age 13. As an avid chess player, he was undoubtedly inspired by the epic showdown of IBM’s Deep Blue against world chess champion and grandmaster Gary Kasparov. Simply repeating the feat with a different technique wouldn’t do at all, so Deepmind turned to another game.
The invention of Go predates chess by about 1000 years or more, and in ancient China Go was one of the “four arts,” a collection of noble aristocratic pastimes including poetry, calligraphy, and music. Go has simpler rules but many more possible moves than chess. Although there is only one type of piece and one type of move per player, the state space complexity of Go is 10170 different board positions, while a chess game can support 1047 different states . Go was named as a noteworthy challenge for AI researchers in a 2001 article [pdf] and in a 2008 xkcd webcomic by Randall Munroe.
Although AlphaGo has since been eclipsed by successive Deepmind game-playing models AlphaGo Zero, AlphaZero, and Muzero, it is still the most famous variant. The 5 game series against Lee Sedol in 2016 had an impact that changed the face of the Go-playing world for the foreseeable future that has since been unmatched by AlphaGo’s more efficient, general, and capable progeny.
AlphaGo combines several neural networks with deep tree search. The networks are used to approximate the policy function, map board states to actions, and as a value function, which estimates the likely outcome of the game for each game state. There are three versions of the policy network: a supervised learning policy network trained to mimic the actions of professional human Go players (pσ), the reinforcement learning policy network (pρ) which is initially cloned from pσ, and a fast rollout policy network (pπ) used to quickly extend tree search to find an end game state. The role of the value network (vθ) is to estimate the likelihood of an eventual win for any state of the game board.
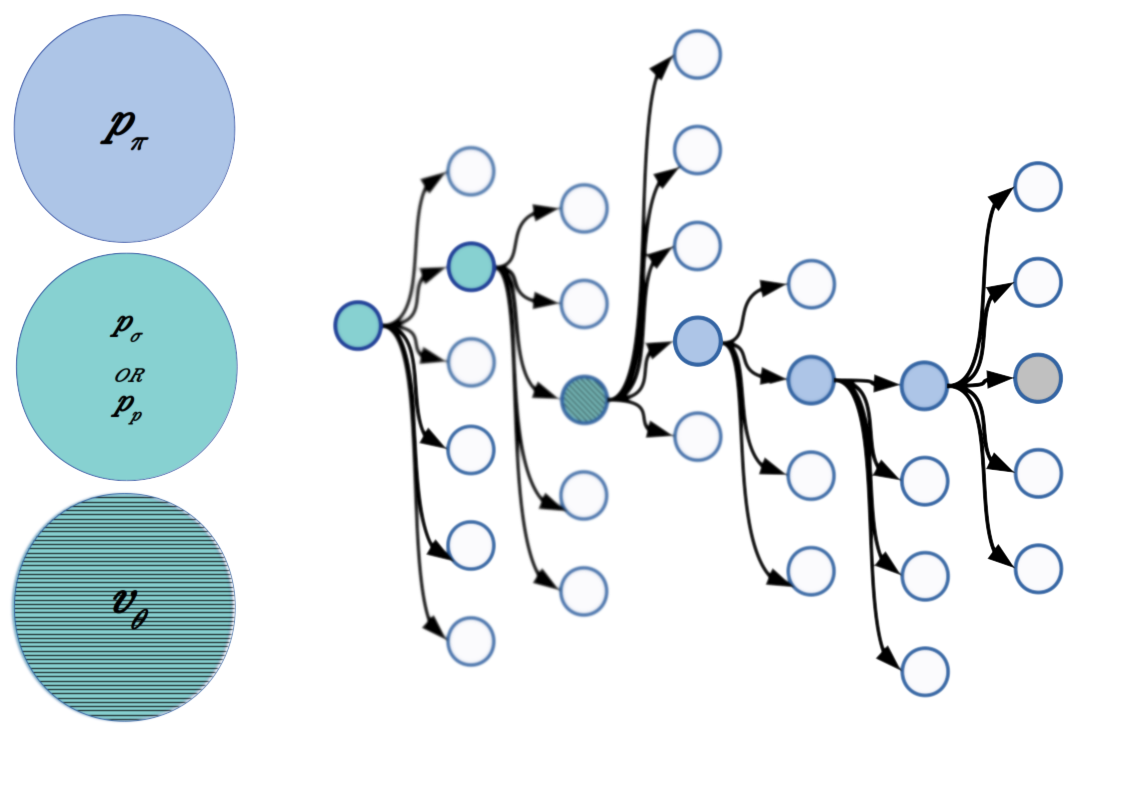
Policy, Value, and Tree Search: At each game state, AlphaGo looks one or two steps into the future using the full policy network (pρ). The value of the game state at this forward-looking branch is estimated by the value network, and this estimate is combined by filling out the tree with a lightweight rollout policy. The low-parameter rollout policy network (pπ) has a fast inference time and is used to extend the search tree out to the eventual end of the game. Inference time for the rollout network is about 1,000 times faster than for the full policy network (on the order of microseconds versus milliseconds). It’s important to note that the action recommendations output by the policy networks are probabilities and tree search is repeated many times. This puts the ‘Monte Carlo’ in Monte Carlo tree search.
Later in 2016, a variant of AlphaGo updated with additional training (now known as AlphaGo Master) began a stealth campaign playing Go online. AlphaGo Master played 60 games over the course of about two months (including three games against top-ranked Ke Jie. On the strength of AlphaGo Master’s online performance, Deepmind secured a live match against Ke Jie at the Future of Go summit, beating the human player three games to none. Perhaps most noteworthy is that AlphaGo Master was described as having a very inhuman style of play, reportedly inspiring Ke Jie to develop an entirely new strategy.
AlphaGo’s victories over the best human Go players in the world cemented its place in history alongside IBM’s Deep Blue and its victory over chess champion Gary Kasparov, but the work wasn’t finished yet. After beating Ke Jie, the AlphaGo system was considered by many to be the best Go player in the world, leading by a wide margin. To continue to develop the system without comparable opponents, AlphaGo turned to a training strategy based entirely on self-play.
Self-play is a powerful training strategy where an agent or (population of agents) plays against itself. This ensures a constantly improving opponent, although it does require special consideration to be given to problems like catastrophic forgetting or overfitting to a specific game style. AlphaGo Zero immediately followed AlphaGo and unlike its predecessor, AlphaGo Zero played without any initial training on human examples. In addition to learning from scratch, AlphaGo Zero combined the various neural network functionality of AlphaGo into a single network outputting the board state value and action probabilities, while still relying on Monte Carlo tree search to fine-tune gameplay. Free from the limitations of human play, AlphaGo Zero managed to overwhelmingly outclass AlphaGo, winning 100 games to 0.
Even compared to AlphaGo Zero, human game players retain some distinct advantages. While AlphaGo and AlphaGo Zero are very good at playing Go, they are immeasurably bad at essentially everything else humans can do. As an example of a small sliver of the things that a human can do better, AlphaGo and AlphaGo Zero can’t play chess at all.
AlphaZero tackled this shortcoming by applying the same network architecture and similar hyperparameters to learn to play chess and shogi (Japanese chess) as well as Go. Each game-specific instance of AlphaZero beat the previous state of the art program. AlphaZero trained on chess beat StockFish with a win, loss, draw, record of 155, 6, and 839, respectively. AlphaZero trained on shogi defeated a shogi engine called Elmo. At Go, AlphaZero even beat the previous best version of AlphaGo Zero, even though the two game-players differ only slightly in the way the model was updated during training.
Without any human gameplay examples the only expert knowledge given to AlphaZero for each game was the set of rules for each game. This isn’t exactly fair, especially in comparison to human players, because it means that for every game position AlphaZero is essentially playing through hundreds or thousands of game scenarios before making a decision in the same environment it experiences during real game play.
It’s sort of like an extremely large-scale version of infinite take-backs, as if a human player were to play a lifetime of matches starting at each board state before making each decision. MuZero, the latest iteration board game engine from Deepmind, replaces the ground-truth game model with a learned model (represented by another deep neural net). The learned model comes into play in three places where previously AlphaZero and company had access to the ground truth game dynamics: during tree search to generate transitions, to determine the actions available, and to designate when the game has reached a terminal state.
In MuZero, each of these responsibilities is delegated to the learned model. This is much more similar to how a human player might evaluate game scenarios, not by playing out each instance in actual games but by imagining what comes next. MuZero managed to exceed (by a slim margin) the performance of AlphaZero in all three game domains of chess, shogi, and Go. In addition, MuZero is vastly more generalizable: the same training algorithm was applied to 57 Atari games and improved on previous state-of-the-art performance on 42 of them.
Compared to previous game engines, the AlphaGo lineage of players had better sample efficiency but worse compute efficiency, as the engines developed by Deepmind always had access to more computation than game engines like Stockfish and Elmo in competition. This is in line with what we expect in trade-offs between sample and computational efficiency in reinforcement learning. The competition between more general lightweight algorithms (like evolutionary strategies) on the one hand and computationally intensive but sample efficient approaches (such as model-based RL) is a defining aspect of deep reinforcement learning that is worth keeping an eye on.

The last stop on our game playing AI journey is a battle for the universe itself, not the universe we inhabit per se but a particular video game universe called Starcraft II. Set in an alternate future, the Starcraft world pits humans against two other alien species in a military struggle for survival. Each side is carefully balanced against the others in terms of unit strength, economy, and tactics. It would probably be an understatement to say comparing Starcraft II to the board games we’ve mentioned so far is like comparing any of those games to tic-tac-toe.
A game of Go may last for a few hundred moves, while a fast-paced Starcraft II match-up will probably be over in less than 20 minutes. During that time high-skill players will be issuing hundreds of commands per minute (aka “actions per minute” or APM), exceeding the number of moves in a typical Go game by an order of magnitude. More importantly, unlike every other game we’ve considered so far, Starcraft II is an incomplete information game. At any given time, most of the map is hidden from a player by a fog-of-war. To win, players must manage both combat and economic strategy across multiple scales in both space and time, and there is no pause to wait for the opposing player to finish their turn.
Deepmind has been working on Starcraft II since at least 2017, when they released the open source development environment PySCII. Toward the end of 2018 AlphaStar took on professional players Dario “TLO” Wünsch and Grzegorz “MaNa” Komincz, defeating them handily in a series of demonstration matches. These matches came with substantial caveats, however.
The demonstration matches were heavily criticized for granting AlphaStar unfair advantages of being able to observe the entire map simultaneously (unlike the focus camera view enjoyed by human players) and the exceptionally precise and high rate of actions taken by the agent. Deepmind did take steps to limit the actions per minute to a level comparable to professional Starcraft II players, but they ignored several important factors in determining realistic effective actions per minute. The first is that human players make a large number of pointless actions, called spamming, deliberately (to increase APM and keep finger muscles warm) and non-deliberately. AlphaStar is also capable of much more accurate actions due to a simplified observations interface, and it doesn’t have to build up any of the dexterity a human player needs to operate a mouse. You can get an idea of the raw observations AlphaStar has to work with in the video below.
TL;DR:
There is still a long way to go before machine agents match overall human gaming prowess, but Deepmind’s gaming research focus has shown a clear progression of substantial progress.
Deepmind’s continuing focus on game playing has led to several machine learning breakthroughs in the past decade. The DQN paper on Atari has become a seminal work in off-policy deep reinforcement learning, while the AlphaGo lineage has compressed the equivalent of several decades of game playing progress into about six years, exceeding previous breakthroughs in chess, checkers, and simpler games. The relatively nascent foray into real time strategy games like Starcraft II remains in very early stages, and still benefits from substantial unfair advantages over human players in observation and action interface. This may remain debatable until an agent is capable of mastering gameplay and the ability to manipulate a mouse and keyboard simultaneously.
In tournaments for chess and other games, it’s typical to constrain the amount of time each player has to make a move. Why not have tournaments with classes based on another metric, like energy consumption? Suddenly the 20 Watt hardware of the human brain is exceptionally competitive again. It might also be worth constraining economic inputs. By some estimates, training AlphaStar to grandmaster level cost nearly $13 million USD, while AlphaGo Zero may have cost more than twice that (at retail cloud compute prices). Constraining open tournaments by energy or economic inputs might sound unrealistic, but it would level the playing field without outright banning computer players and lead to interesting developments in efficient machine learning.
We can look at the progress in machine learning discussed in this article as a sure sign that humans are obsolete, at least as game players. For example, Lee Sedol, who played a valiant game against AlphaGo, has retired from professional play in response to the dominance of the AlphaGo lineage. A more optimistic viewpoint is that the phenomenal performance of deep learning game engines developed in the 2010s have provided an additional window into what is possible in the games humans love to play.

Humans have played board games at least since the ancient Egyptian game of Senet, with game pieces found in burials dating back to 3500 BC (although the precursors of Backgammon may be older). Playing in general is an essential part of learning for animals, including humans. Deepmind has proven games are also a fertile substrate for developing machine learning and artificial intelligence.
Games, especially classic board games like chess and Go (Go is generally capitalized in English to differentiate from the verb) make good candidates for developing machine game players thanks to a few shared characteristics. Games where self-play is possible are especially ripe candidates for developing capable agents as an agent experiences an environment with an adaptive difficulty provided by an improving opponent.
Games also tend to have a definite outcome (win, draw, or lose), are deterministic in their actions, and have no hidden information. This simplifies the learning process substantially compared to real world scenarios that incorporate uncertainty from unknowns, stochastic processes, and ambiguous outcomes. Correspondingly chess, go, and classic video games make good toy problems for AI development, albeit toy problems with more possible game states than there are atoms in the universe.
Eventually the characteristics that make board games good subjects for developing AI become a hindrance. Imperfect information and long time horizons are an intrinsic part of the world we live in, and if researchers want to develop a general intelligence capable of dealing with it they need to find harder games. Modern video games provide such a venue, with fog-of-war uncertainty and very long time horizons to complicate an already complex state space.
Several of the largest artificial intelligence research institutions have teams devoted to real-time-strategy video games: Deepmind has focused on Starcraft II while OpenAI has focused their energies on developing Dota 2. These efforts represent the pinnacle of game-playing machines, although there are nascent efforts to teach machines to play open-ended, creative games like Microsoft’s Malmö project built on top of Minecraft.
Under the Universal Approximation Theorem (UAT), a neural network with a single hidden layer and a non-linear activation function is capable of approximating any function with a finite (but sometimes quite large) number of activation nodes in the hidden layer. This is conceptually similar to performing Fourier decomposition of a signal or polynomial fits, shown here. The more Fourier bases, higher polynomial degree, or number of activation nodes in the hidden layer, the better a function can be approximated.
The trick that differentiates modern efforts in machine gaming from game playing accomplishments of the 1990s like IBM’s Deep Blue chess playing computer and the University of Alberta’s Chinook checkers playing program is the liberal application of deep neural networks. This is a useful thing to do thanks to a theorem described in the late 1980s/early 1990s by Cybenko and Hornik called the Universal Approximation Theorem (UAT). Under the UAT, even a single-hidden layer feed-forward neural network with a non-linear activation function can approximate any arbitrary function.
Universal approximation with neural networks is a little like polynomial fitting. Where a polynomial fit stores the input/output relation in a series of coefficients, a neural network represents the transformation in network weights. In both cases increasing the number of activation nodes (or the degree of the polynomial) makes for a better representation.
Under the original formulation of the UAT, based on shallow networks, the width of the network can grow exponentially. Much of the deep learning revolution in machine learning over the past decade has come from the appreciation that depth is empirically much more useful than width in neural networks, and indeed the UAT has been updated by Zhou Lu and colleagues to reflect this finding theoretically.
Bringing it all together, deep neural networks can be used to approximate any continuous function. What’s more, they can be coaxed to do a reasonably good job at generalizing to unseen data, so long as the network is trained on a sufficiently large number of training samples. So we can describe the role of neural networks in reinforcement learning as high-dimensional function approximators.
Unlike image classification, which only has one place to apply a deep neural network (the transformation from input images to class labels), in deep reinforcement learning there are many different functions to approximate including value functions, action-value functions, and input-action pairings. In practice these networks tend to be small, with as little as a single hidden layer of less than 32 activations.
In fact simple tasks like balancing a rod on a rail can be accomplished with no more than 7 binary connections in a single hidden layer feed-forward network. The networks used for basic RL experiments may seem paltry next to the 100+ layers used in state-of-the-art image tasks, but this is starting to change with the rise of procedurally-generated environments (which discourage overfitting) and more challenging tasks.
You might actually say that the history of game-playing at Deepmind actually predates the formation of the company itself. Demis Hassabis, the CEO and co-founder of Deepmind, has a long-standing obsession with gaming that predates the Deepmind’s victories over top players in Go and Starcraft II, before Google acquired the company for about £400/$660 million GBP/USD in 2014, and even before the company was founded in 2010. Demis Hassabis started his career making video games.
In fact, he was building games for Bullfrog Productions before he went on to study computer science at Cambridge University in England. After graduating he worked on games such as Black & White at Lionhead Studios before going back to university for a PhD in neuroscience and finally founding Deepmind in 2010 with Shane Legg and Mustafa Suleyman. It would be 6 years before Deepmind shocked the world with a victory over the reigning world (human) champion of Go, Lee Sedol (https://en.wikipedia.org/wiki/Lee_Sedol). The Go project eventually culminated (so far) in more general game playing models AlphaZero and MuZero, but before diving into the lineage of Deepmind’s Go champion let’s take a little detour to the arcade.
DQN in a nutshell: The DQN algorithm works by gathering game play rollouts using an action-value policy. Game transitions are sampled from the rollout buffer, which includes episodes from multiple training epochs. The action-value network, Q, is updated at each training episode to match the rewards output by the environment and the values estimated by Qt , the action-value target network. Screenshot from a homebrew Atari game is in the public domain
Deepmind’s initial foray into learning classic Atari 2600 games, spearheaded by Volodymyr Mnih, learned to play seven games, achieving average human level performance on three of the seven. That was 2013, three years after the founding of the company. In 2015 they expanded the battery of games to a comprehensive Atari suite of 49 games, matching or beating the performance of a professional human games tester on 23 of them.
That may sound a bit disappointing, but the DQN algorithm game-learner utilized the same network architecture and hyperparameters to learn each game. Despite impressive performance within 25% of human ability on the majority of games, a few Atari games remain “RL-hard.” These are extremely difficult for a machine to learn. Most of these games rely heavily on exploration, and include the infamous Montezuma’s revenge as well as Gravitar and Private Eye.
In the span of two years of development time between the initial publication of the DQN Atari learner and the human-level performance paper, the team at Deepmind improved the stability of training by incorporating experience replay and a second target function with an occasional, periodic update schedule.
These changes led to impressive performance, including the famous Breakout solution. After several hundred training updates the agent learns an optimal strategy: tunnel through the edge blocks and serve the ball behind the wall to take out many bricks at once.
The DQN paper on Atari is a notable example of end-to-end deep learning. The inputs are images generated by the game emulator, and the outputs are actions corresponding to pressing a specific button or buttons on the Atari console. That this work was going on at Deepmind probably played no small part in Google’s decision to buy the company in 2014.
But Atari games are all very similar, and though they can be difficult to master for humans and machines alike, they were never considered to be a lofty intellectual pursuit like Chess. To cement their status in game-playing history alongside the likes of Deep Blue vs. Kasparov, Deepmind would need to take on the noble game of Go.
Before beginning a precocious career as a video game developer Demis Hassabis was a keen chess player, achieving the rank of master with an Elo rating of 2300 at age 13. As an avid chess player, he was undoubtedly inspired by the epic showdown of IBM’s Deep Blue against world chess champion and grandmaster Gary Kasparov. Simply repeating the feat with a different technique wouldn’t do at all, so Deepmind turned to another game.
The invention of Go predates chess by about 1000 years or more, and in ancient China Go was one of the “four arts,” a collection of noble aristocratic pastimes including poetry, calligraphy, and music. Go has simpler rules but many more possible moves than chess. Although there is only one type of piece and one type of move per player, the state space complexity of Go is 10170 different board positions, while a chess game can support 1047 different states . Go was named as a noteworthy challenge for AI researchers in a 2001 article [pdf] and in a 2008 xkcd webcomic by Randall Munroe.
Although AlphaGo has since been eclipsed by successive Deepmind game-playing models AlphaGo Zero, AlphaZero, and Muzero, it is still the most famous variant. The 5 game series against Lee Sedol in 2016 had an impact that changed the face of the Go-playing world for the foreseeable future that has since been unmatched by AlphaGo’s more efficient, general, and capable progeny.
AlphaGo combines several neural networks with deep tree search. The networks are used to approximate the policy function, map board states to actions, and as a value function, which estimates the likely outcome of the game for each game state. There are three versions of the policy network: a supervised learning policy network trained to mimic the actions of professional human Go players (pσ), the reinforcement learning policy network (pρ) which is initially cloned from pσ, and a fast rollout policy network (pπ) used to quickly extend tree search to find an end game state. The role of the value network (vθ) is to estimate the likelihood of an eventual win for any state of the game board.
Policy, Value, and Tree Search: At each game state, AlphaGo looks one or two steps into the future using the full policy network (pρ). The value of the game state at this forward-looking branch is estimated by the value network, and this estimate is combined by filling out the tree with a lightweight rollout policy. The low-parameter rollout policy network (pπ) has a fast inference time and is used to extend the search tree out to the eventual end of the game. Inference time for the rollout network is about 1,000 times faster than for the full policy network (on the order of microseconds versus milliseconds). It’s important to note that the action recommendations output by the policy networks are probabilities and tree search is repeated many times. This puts the ‘Monte Carlo’ in Monte Carlo tree search.
Later in 2016, a variant of AlphaGo updated with additional training (now known as AlphaGo Master) began a stealth campaign playing Go online. AlphaGo Master played 60 games over the course of about two months (including three games against top-ranked Ke Jie. On the strength of AlphaGo Master’s online performance, Deepmind secured a live match against Ke Jie at the Future of Go summit, beating the human player three games to none. Perhaps most noteworthy is that AlphaGo Master was described as having a very inhuman style of play, reportedly inspiring Ke Jie to develop an entirely new strategy.
AlphaGo’s victories over the best human Go players in the world cemented its place in history alongside IBM’s Deep Blue and its victory over chess champion Gary Kasparov, but the work wasn’t finished yet. After beating Ke Jie, the AlphaGo system was considered by many to be the best Go player in the world, leading by a wide margin. To continue to develop the system without comparable opponents, AlphaGo turned to a training strategy based entirely on self-play.
Self-play is a powerful training strategy where an agent or (population of agents) plays against itself. This ensures a constantly improving opponent, although it does require special consideration to be given to problems like catastrophic forgetting or overfitting to a specific game style. AlphaGo Zero immediately followed AlphaGo and unlike its predecessor, AlphaGo Zero played without any initial training on human examples. In addition to learning from scratch, AlphaGo Zero combined the various neural network functionality of AlphaGo into a single network outputting the board state value and action probabilities, while still relying on Monte Carlo tree search to fine-tune gameplay. Free from the limitations of human play, AlphaGo Zero managed to overwhelmingly outclass AlphaGo, winning 100 games to 0.
Even compared to AlphaGo Zero, human game players retain some distinct advantages. While AlphaGo and AlphaGo Zero are very good at playing Go, they are immeasurably bad at essentially everything else humans can do. As an example of a small sliver of the things that a human can do better, AlphaGo and AlphaGo Zero can’t play chess at all.
AlphaZero tackled this shortcoming by applying the same network architecture and similar hyperparameters to learn to play chess and shogi (Japanese chess) as well as Go. Each game-specific instance of AlphaZero beat the previous state of the art program. AlphaZero trained on chess beat StockFish with a win, loss, draw, record of 155, 6, and 839, respectively. AlphaZero trained on shogi defeated a shogi engine called Elmo. At Go, AlphaZero even beat the previous best version of AlphaGo Zero, even though the two game-players differ only slightly in the way the model was updated during training.
Without any human gameplay examples the only expert knowledge given to AlphaZero for each game was the set of rules for each game. This isn’t exactly fair, especially in comparison to human players, because it means that for every game position AlphaZero is essentially playing through hundreds or thousands of game scenarios before making a decision in the same environment it experiences during real game play.
It’s sort of like an extremely large-scale version of infinite take-backs, as if a human player were to play a lifetime of matches starting at each board state before making each decision. MuZero, the latest iteration board game engine from Deepmind, replaces the ground-truth game model with a learned model (represented by another deep neural net). The learned model comes into play in three places where previously AlphaZero and company had access to the ground truth game dynamics: during tree search to generate transitions, to determine the actions available, and to designate when the game has reached a terminal state.
In MuZero, each of these responsibilities is delegated to the learned model. This is much more similar to how a human player might evaluate game scenarios, not by playing out each instance in actual games but by imagining what comes next. MuZero managed to exceed (by a slim margin) the performance of AlphaZero in all three game domains of chess, shogi, and Go. In addition, MuZero is vastly more generalizable: the same training algorithm was applied to 57 Atari games and improved on previous state-of-the-art performance on 42 of them.
Compared to previous game engines, the AlphaGo lineage of players had better sample efficiency but worse compute efficiency, as the engines developed by Deepmind always had access to more computation than game engines like Stockfish and Elmo in competition. This is in line with what we expect in trade-offs between sample and computational efficiency in reinforcement learning. The competition between more general lightweight algorithms (like evolutionary strategies) on the one hand and computationally intensive but sample efficient approaches (such as model-based RL) is a defining aspect of deep reinforcement learning that is worth keeping an eye on.
The last stop on our game playing AI journey is a battle for the universe itself, not the universe we inhabit per se but a particular video game universe called Starcraft II. Set in an alternate future, the Starcraft world pits humans against two other alien species in a military struggle for survival. Each side is carefully balanced against the others in terms of unit strength, economy, and tactics. It would probably be an understatement to say comparing Starcraft II to the board games we’ve mentioned so far is like comparing any of those games to tic-tac-toe.
A game of Go may last for a few hundred moves, while a fast-paced Starcraft II match-up will probably be over in less than 20 minutes. During that time high-skill players will be issuing hundreds of commands per minute (aka “actions per minute” or APM), exceeding the number of moves in a typical Go game by an order of magnitude. More importantly, unlike every other game we’ve considered so far, Starcraft II is an incomplete information game. At any given time, most of the map is hidden from a player by a fog-of-war. To win, players must manage both combat and economic strategy across multiple scales in both space and time, and there is no pause to wait for the opposing player to finish their turn.
Deepmind has been working on Starcraft II since at least 2017, when they released the open source development environment PySCII. Toward the end of 2018 AlphaStar took on professional players Dario “TLO” Wünsch and Grzegorz “MaNa” Komincz, defeating them handily in a series of demonstration matches. These matches came with substantial caveats, however.
The demonstration matches were heavily criticized for granting AlphaStar unfair advantages of being able to observe the entire map simultaneously (unlike the focus camera view enjoyed by human players) and the exceptionally precise and high rate of actions taken by the agent. Deepmind did take steps to limit the actions per minute to a level comparable to professional Starcraft II players, but they ignored several important factors in determining realistic effective actions per minute. The first is that human players make a large number of pointless actions, called spamming, deliberately (to increase APM and keep finger muscles warm) and non-deliberately. AlphaStar is also capable of much more accurate actions due to a simplified observations interface, and it doesn’t have to build up any of the dexterity a human player needs to operate a mouse. You can get an idea of the raw observations AlphaStar has to work with in the video below.
TL;DR:
There is still a long way to go before machine agents match overall human gaming prowess, but Deepmind’s gaming research focus has shown a clear progression of substantial progress.
Deepmind’s continuing focus on game playing has led to several machine learning breakthroughs in the past decade. The DQN paper on Atari has become a seminal work in off-policy deep reinforcement learning, while the AlphaGo lineage has compressed the equivalent of several decades of game playing progress into about six years, exceeding previous breakthroughs in chess, checkers, and simpler games. The relatively nascent foray into real time strategy games like Starcraft II remains in very early stages, and still benefits from substantial unfair advantages over human players in observation and action interface. This may remain debatable until an agent is capable of mastering gameplay and the ability to manipulate a mouse and keyboard simultaneously.
In tournaments for chess and other games, it’s typical to constrain the amount of time each player has to make a move. Why not have tournaments with classes based on another metric, like energy consumption? Suddenly the 20 Watt hardware of the human brain is exceptionally competitive again. It might also be worth constraining economic inputs. By some estimates, training AlphaStar to grandmaster level cost nearly $13 million USD, while AlphaGo Zero may have cost more than twice that (at retail cloud compute prices). Constraining open tournaments by energy or economic inputs might sound unrealistic, but it would level the playing field without outright banning computer players and lead to interesting developments in efficient machine learning.
We can look at the progress in machine learning discussed in this article as a sure sign that humans are obsolete, at least as game players. For example, Lee Sedol, who played a valiant game against AlphaGo, has retired from professional play in response to the dominance of the AlphaGo lineage. A more optimistic viewpoint is that the phenomenal performance of deep learning game engines developed in the 2010s have provided an additional window into what is possible in the games humans love to play.



