Deep Learning
Computational Needs for Computer Vision (CV) in AI & ML Systems
September 14, 2020
16 min read


Computer vision (CV) is a major task for modern Artificial Intelligence (AI) and Machine Learning (ML) systems. It’s accelerating nearly every domain in the tech industry enabling organizations to revolutionize the way machines and business systems work.
Academically, it is a well-established area of computer science and many decades worth of research work have gone into this field. However, the use of deep neural networks has recently revolutionized the CV field and given it new oxygen.
There is a diverse array of application areas for computer vision. In this article, we briefly show you the common challenges associated with a CV system when it employs modern ML algorithms. For our discussion, we focus on two of the most prominent (and technically challenging) use cases of computer vision:
Both of these use cases present a high degree of complexity, along with other associated challenges.

Image source: Wikipedia
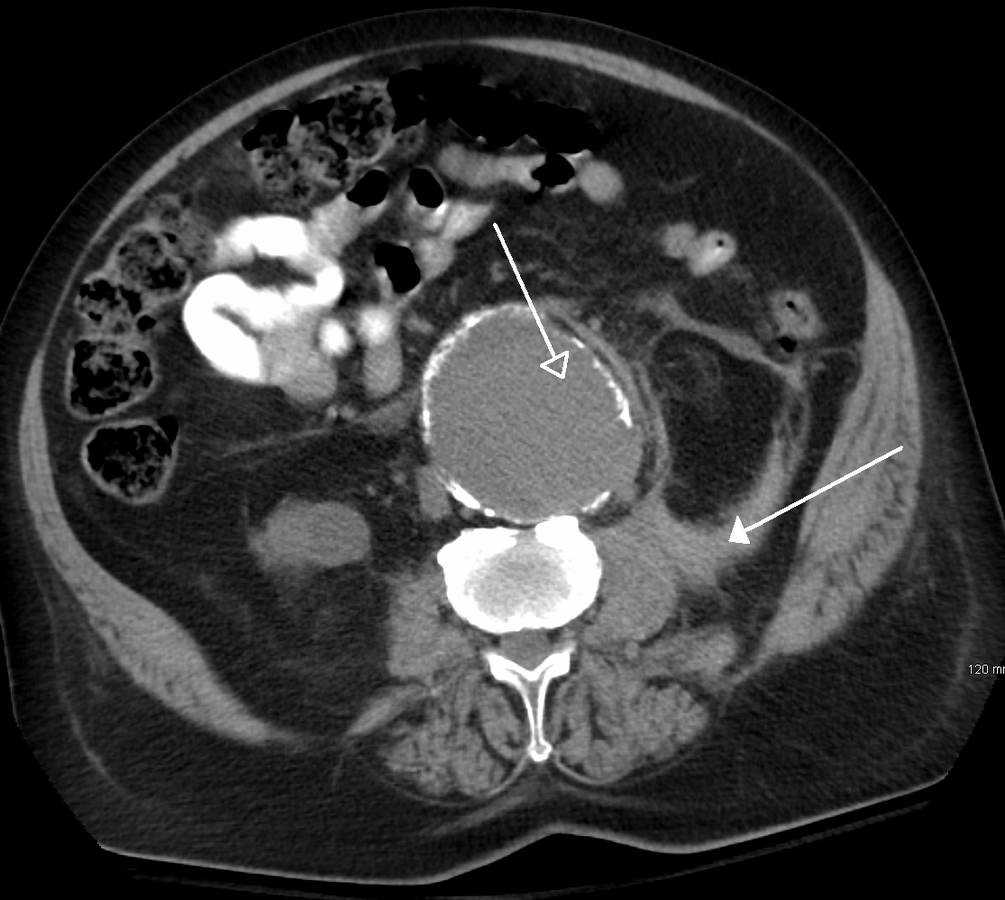
Image source: Wikipedia
A common challenge is the large number of tasks associated with a given use case. For example, the autonomous driving use case includes not only object detection but also object classification, segmentation, motion detection, etc. On top of it, these systems are expected to make this kind of CV processing happening in a fraction of a second, and convey a high-probability decision to the higher-level supervisory control system responsible for the ultimate task of driving.
Furthermore, not one, but multiple such CV systems/algorithms are often at play in any respectable autonomous driving system. The demand for parallel processing is high in those situations and this leads to high stress on the underlying computing machinery. If multiple neural networks are used at the same time, they may be sharing the common system storage and compete with each other for a common pool of resources.
In the case of medical imaging, the performance of the computer vision system is judged against highly experienced radiologists and clinical professionals who understand the pathology behind an image. Moreover, in most cases, the task involves identifying rare diseases with very low prevalence rates. This makes the training-data sparse and rarefied (i.e. not enough training images can be found). Consequently, the Deep Learning (DL) architecture has to compensate for this by adding clever processing and architectural complexity. This, of course, leads to enhanced computational complexity.
Learn how Artificial Intelligence (AI) is changing medical imaging into one of the fastest growing deep learning healthcare segments.
Download Whitepaper
Training machines on image and video files is a serious data-intensive operation.
A singular image file is a multi-dimensional, multi-megabytes digital entity containing only a tiny fraction of ‘insight’ in the context of the whole ‘intelligent image analysis’ task. In contrast, a similar-sized sales data table can lend much more insight into the ML algorithm with the same expenditure on the computational hardware. This fact is worth remembering while talking about the scale of data and the computing required for modern computer vision pipelines.
Unfortunately, one or two (or even a set of hundred) images is usually not enough to fully train on. Robust, generalizable, production-quality deep learning systems require millions of images to train on.
Here, we list some of the most popular ones (consisting of both static images and video clips):
ImageNet is an ongoing research effort to provide researchers around the world with an easily accessible image database. This project is inspired by a growing sentiment within the image and vision research field – the need for more data. It is organized according to the WordNet hierarchy. Each meaningful concept in WordNet, possibly described by multiple words or word phrases, is called a “synonym set” or “synset”. There are more than 100,000 synsets in WordNet. ImageNet aims to provide on average 1000 images to illustrate each synset.
This is one of the largest and open-sourced datasets of face images with gender and age labels for training. In total, there are 523,051 face images in this dataset where 460,723 face images are obtained from 20,284 celebrities from IMDB and 62,328 from Wikipedia.
COCO or Common Objects in Context is a large-scale object detection, segmentation, and captioning dataset. The dataset contains photos of 91 object types which are easily recognizable and have a total of 2.5 million labeled instances in 328k images.
This dataset is used for the evaluation of articulated human pose estimation. It includes around 25K images containing over 40K people with annotated body joints. Here, each image is extracted from a YouTube video and provided with preceding ann following un-annotated frames. Overall the dataset covers 410 human activities and each image is provided with an activity label.
This dataset is a large collection of densely-labeled video clips that show humans performing pre-defined basic actions with everyday objects. It was created by a large number of crowd workers which allows ML models to develop a fine-grained understanding of basic actions that occur in the physical world.
It’s needless to emphasize that to work with such large-scale datasets, many of which are continuously updated and expanded, engineers need robust, fail-proof, high-performance storage solutions to be an integral part of a DL-based CV system. In real-life scenarios, terabytes of image/video data can be generated within a short span of time by end-of-line systems like automobile/drone cameras or x-ray/MRI machines in a network of hundreds of hospitals/clinics.
That seriously puts a whole new spin on the term “Big Data.”
There are multiple considerations and dimensions of choosing and adopting the right data storage for your computer vision task. Some of them are as follows,
General-purpose CPUs struggle when operating on a large amount of data e.g., performing linear algebra operations on matrices with tens or hundreds thousand floating-point numbers. Under the hood, deep neural networks are mostly composed of operations like matrix multiplications and vector additions.
GPUs were developed (primarily catering to the video gaming industry) to handle a massive degree of parallel computations using thousands of tiny computing cores. They also feature large memory bandwidth to deal with the rapid dataflow (processing unit to cache to the slower main memory and back), needed for these computations when the neural network is training through hundreds of epochs. This makes them the ideal commodity hardware to deal with the computation load of computer vision tasks.
This is a nice graphical comparison of GPU vs. CPU from this Medium post:
.png)
And here is a simple table summarizing the key differences (from this post):

On a high-level, the main features you need to look for while choosing a GPU for your DL system, are:
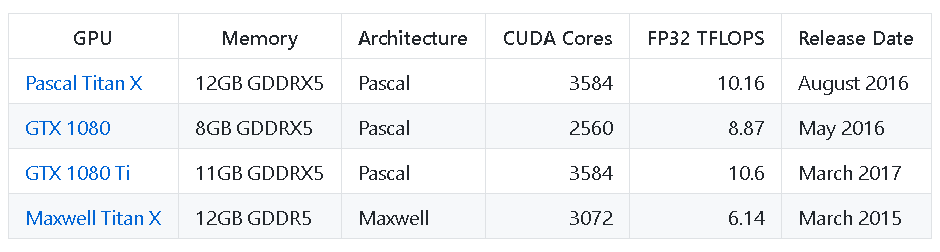
There are many choices of GPUs on the market, and this can certainly overwhelm the average user with trying to figure out what to buy for their system. There are some good benchmarking strategies that have been published over the years to guide a prospective buyer in this regard.
A good benchmarking exercise must consider multiple varieties of (a) Convolutional Neural Network (CNN) architecture, (b) GPU, and (c) widely used datasets.
For example, this excellent article here considers the following:
Also, multiple dimensions of performance must be considered for a good benchmark. For example, the article above mentions three primary indices:
An older but highly popular and rigorously tested benchmarking exercise can be found in this open-source Github repo (there have been many GPU advances since then, with a new line from NVIDIA that blow away older GPUs in performance: RTX 3070, RTX 3080, RTX 3090).
The table from this exercise looks like the following:
Benchmarked GPUs
AlexNet Performance
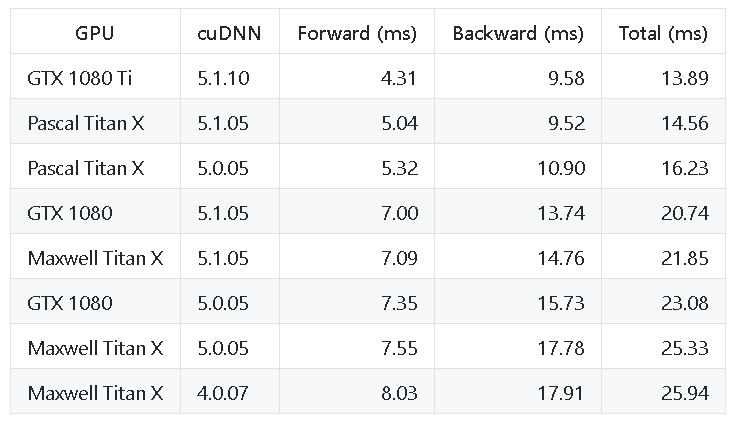
Inception V1 Performance
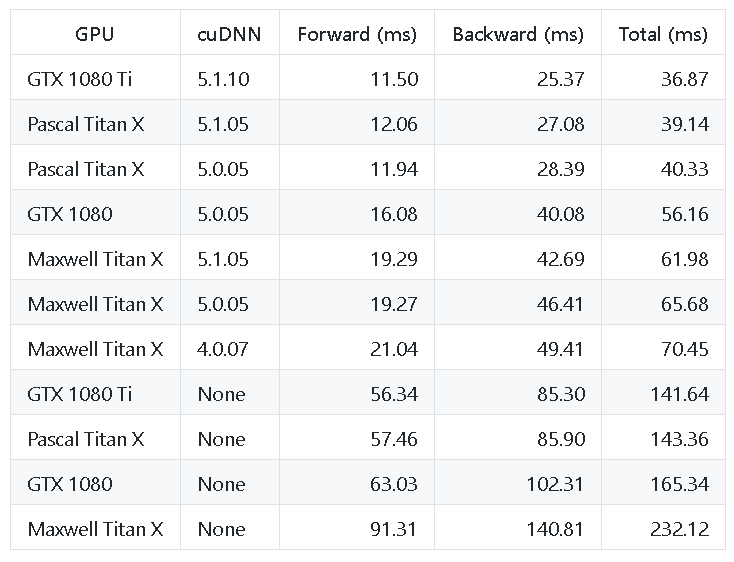
ResNet-50 Performance
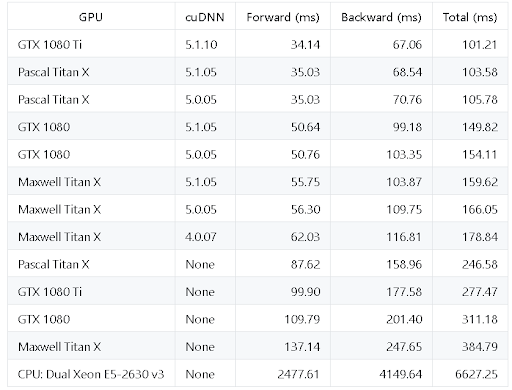
Although the fundamental computations behind deep learning are well understood, the way they are used in practice can be surprisingly diverse. For example, a matrix multiplication may be compute-bound, bandwidth-bound, or occupancy-bound, based on the size of the matrices being multiplied and the kernel implementation. Because every deep learning model uses these operations with different parameters, the optimization space for hardware and software targeting deep learning is large and underspecified.
DeepBench attempts to answer the question, “Which hardware provides the best performance on the basic operations used for deep neural networks?” The primary purpose is to benchmark the core operations that are important to deep learning across a wide variety of hardware platforms.
They employ the following core operations to evaluate the competing hardware platforms:
The results are available on their Github repo in the form of simple Excel files.
In this article, we started with the characteristics and challenges associated with modern large-scale computer vision tasks, as aided by complex deep learning networks. The challenges can be well understood in the context of two of the most promising applications – autonomous driving and medical imaging.
We also went over the datasets, storage, and computing (GPU vs. CPU) requirements for the CV systems and discussed some key desirable features that this kind of system should possess.
Finally, we talked about a few open-source resources that benchmark hardware platforms for high-end deep learning/CV tasks and showed some key performance benchmark tables for popular hardware choices.
Computer vision will continue to advance in the coming years as breakthroughs in hardware and algorithms lead to new performance gains.

Have any questions about AI workstations or servers that can handle computer vision?
Contact Exxact Today
Computer vision (CV) is a major task for modern Artificial Intelligence (AI) and Machine Learning (ML) systems. It’s accelerating nearly every domain in the tech industry enabling organizations to revolutionize the way machines and business systems work.
Academically, it is a well-established area of computer science and many decades worth of research work have gone into this field. However, the use of deep neural networks has recently revolutionized the CV field and given it new oxygen.
There is a diverse array of application areas for computer vision. In this article, we briefly show you the common challenges associated with a CV system when it employs modern ML algorithms. For our discussion, we focus on two of the most prominent (and technically challenging) use cases of computer vision:
Both of these use cases present a high degree of complexity, along with other associated challenges.
Image source: Wikipedia
Image source: Wikipedia
A common challenge is the large number of tasks associated with a given use case. For example, the autonomous driving use case includes not only object detection but also object classification, segmentation, motion detection, etc. On top of it, these systems are expected to make this kind of CV processing happening in a fraction of a second, and convey a high-probability decision to the higher-level supervisory control system responsible for the ultimate task of driving.
Furthermore, not one, but multiple such CV systems/algorithms are often at play in any respectable autonomous driving system. The demand for parallel processing is high in those situations and this leads to high stress on the underlying computing machinery. If multiple neural networks are used at the same time, they may be sharing the common system storage and compete with each other for a common pool of resources.
In the case of medical imaging, the performance of the computer vision system is judged against highly experienced radiologists and clinical professionals who understand the pathology behind an image. Moreover, in most cases, the task involves identifying rare diseases with very low prevalence rates. This makes the training-data sparse and rarefied (i.e. not enough training images can be found). Consequently, the Deep Learning (DL) architecture has to compensate for this by adding clever processing and architectural complexity. This, of course, leads to enhanced computational complexity.
Learn how Artificial Intelligence (AI) is changing medical imaging into one of the fastest growing deep learning healthcare segments.
Download Whitepaper
Training machines on image and video files is a serious data-intensive operation.
A singular image file is a multi-dimensional, multi-megabytes digital entity containing only a tiny fraction of ‘insight’ in the context of the whole ‘intelligent image analysis’ task. In contrast, a similar-sized sales data table can lend much more insight into the ML algorithm with the same expenditure on the computational hardware. This fact is worth remembering while talking about the scale of data and the computing required for modern computer vision pipelines.
Unfortunately, one or two (or even a set of hundred) images is usually not enough to fully train on. Robust, generalizable, production-quality deep learning systems require millions of images to train on.
Here, we list some of the most popular ones (consisting of both static images and video clips):
ImageNet is an ongoing research effort to provide researchers around the world with an easily accessible image database. This project is inspired by a growing sentiment within the image and vision research field – the need for more data. It is organized according to the WordNet hierarchy. Each meaningful concept in WordNet, possibly described by multiple words or word phrases, is called a “synonym set” or “synset”. There are more than 100,000 synsets in WordNet. ImageNet aims to provide on average 1000 images to illustrate each synset.
This is one of the largest and open-sourced datasets of face images with gender and age labels for training. In total, there are 523,051 face images in this dataset where 460,723 face images are obtained from 20,284 celebrities from IMDB and 62,328 from Wikipedia.
COCO or Common Objects in Context is a large-scale object detection, segmentation, and captioning dataset. The dataset contains photos of 91 object types which are easily recognizable and have a total of 2.5 million labeled instances in 328k images.
This dataset is used for the evaluation of articulated human pose estimation. It includes around 25K images containing over 40K people with annotated body joints. Here, each image is extracted from a YouTube video and provided with preceding ann following un-annotated frames. Overall the dataset covers 410 human activities and each image is provided with an activity label.
This dataset is a large collection of densely-labeled video clips that show humans performing pre-defined basic actions with everyday objects. It was created by a large number of crowd workers which allows ML models to develop a fine-grained understanding of basic actions that occur in the physical world.
It’s needless to emphasize that to work with such large-scale datasets, many of which are continuously updated and expanded, engineers need robust, fail-proof, high-performance storage solutions to be an integral part of a DL-based CV system. In real-life scenarios, terabytes of image/video data can be generated within a short span of time by end-of-line systems like automobile/drone cameras or x-ray/MRI machines in a network of hundreds of hospitals/clinics.
That seriously puts a whole new spin on the term “Big Data.”
There are multiple considerations and dimensions of choosing and adopting the right data storage for your computer vision task. Some of them are as follows,
General-purpose CPUs struggle when operating on a large amount of data e.g., performing linear algebra operations on matrices with tens or hundreds thousand floating-point numbers. Under the hood, deep neural networks are mostly composed of operations like matrix multiplications and vector additions.
GPUs were developed (primarily catering to the video gaming industry) to handle a massive degree of parallel computations using thousands of tiny computing cores. They also feature large memory bandwidth to deal with the rapid dataflow (processing unit to cache to the slower main memory and back), needed for these computations when the neural network is training through hundreds of epochs. This makes them the ideal commodity hardware to deal with the computation load of computer vision tasks.
This is a nice graphical comparison of GPU vs. CPU from this Medium post:
And here is a simple table summarizing the key differences (from this post):
On a high-level, the main features you need to look for while choosing a GPU for your DL system, are:
There are many choices of GPUs on the market, and this can certainly overwhelm the average user with trying to figure out what to buy for their system. There are some good benchmarking strategies that have been published over the years to guide a prospective buyer in this regard.
A good benchmarking exercise must consider multiple varieties of (a) Convolutional Neural Network (CNN) architecture, (b) GPU, and (c) widely used datasets.
For example, this excellent article here considers the following:
Also, multiple dimensions of performance must be considered for a good benchmark. For example, the article above mentions three primary indices:
An older but highly popular and rigorously tested benchmarking exercise can be found in this open-source Github repo (there have been many GPU advances since then, with a new line from NVIDIA that blow away older GPUs in performance: RTX 3070, RTX 3080, RTX 3090).
The table from this exercise looks like the following:
Benchmarked GPUs
AlexNet Performance
Inception V1 Performance
ResNet-50 Performance
Although the fundamental computations behind deep learning are well understood, the way they are used in practice can be surprisingly diverse. For example, a matrix multiplication may be compute-bound, bandwidth-bound, or occupancy-bound, based on the size of the matrices being multiplied and the kernel implementation. Because every deep learning model uses these operations with different parameters, the optimization space for hardware and software targeting deep learning is large and underspecified.
DeepBench attempts to answer the question, “Which hardware provides the best performance on the basic operations used for deep neural networks?” The primary purpose is to benchmark the core operations that are important to deep learning across a wide variety of hardware platforms.
They employ the following core operations to evaluate the competing hardware platforms:
The results are available on their Github repo in the form of simple Excel files.
In this article, we started with the characteristics and challenges associated with modern large-scale computer vision tasks, as aided by complex deep learning networks. The challenges can be well understood in the context of two of the most promising applications – autonomous driving and medical imaging.
We also went over the datasets, storage, and computing (GPU vs. CPU) requirements for the CV systems and discussed some key desirable features that this kind of system should possess.
Finally, we talked about a few open-source resources that benchmark hardware platforms for high-end deep learning/CV tasks and showed some key performance benchmark tables for popular hardware choices.
Computer vision will continue to advance in the coming years as breakthroughs in hardware and algorithms lead to new performance gains.
Have any questions about AI workstations or servers that can handle computer vision?
Contact Exxact Today



