Deep Learning
Accelerated Automatic Differentiation with JAX: How Does it Stack Up Against Autograd, TensorFlow, and PyTorch?
August 31, 2020
14 min read


Featured image from photographers Austin Kirk and Adam R on Pixabay.
Automatic differentiation underlies the vast majority of success in modern deep learning. This makes a big difference in development time for researchers iterating over models and experiments. Before widely available tools for automatic differentiation, programmers had to “roll their own” gradients, which is not only time-consuming but introduces a substantial coding surface that increases the probability of accumulating disastrous bugs.
Libraries like the well-known TensorFlow and PyTorch keep track of gradients over neural network parameters during training, and they each contain high-level APIs for implementing the most commonly used neural network functionality for deep learning. While this is ideal for production and scaling models to deployment, it leaves something to be desired if you want to build something a little off the beaten path. Autograd is a versatile library for automatic differentiation of native Python and NumPy code, and it’s ideal for combining automatic differentiation with low-level implementations of mathematical concepts to build not only new models, but new types of models (including hybrid physics and neural-based learning models).
While it is a flexible library with an inviting learning curve (NumPy users can jump in at the deep end), Autograd is no longer under active development and it tends to be too slow for medium to large-scale experiments. Development for running Autograd on GPUs was never completed, and therefore training is limited by the execution time of native NumPy code. Consequently JAX is a better choice of automatic differentiation libraries for many serious projects, thanks to just-in-time compilation and support for hardware acceleration.
JAX is the immediate successor to the Autograd library: all four of the main developers of Autograd have contributed to JAX, with two of them working on it full-time at Google Brain. JAX is a Python library that combines hardware acceleration and automatic differentiation with XLA, compiled instructions for faster linear algebra methods, often with improvements to memory usage as well. JAX utilizes the grad function transformation to convert a function into a function that returns the original function’s gradient, just like Autograd. Beyond that, JAX offers a function transformation jit for just-in-time compilation of existing functions and vmap and pmap for vectorization and parallelization, respectively. JAX also will run your models on a GPU (or TPU) if available.
We implemented a simple, single-hidden layer MLP in JAX, Autograd, Tensorflow 2.0 and PyTorch, along with a training loop to “fit” a classification problem of random noise. We tried to implement these all in the same style with a low-level implementation based on matrix multiplies, but you’ll see that we had to take a few shortcuts to implement the model in PyTorch with GPU support.
These implementations provide a baseline for comparing the performance efficiency of each library, although our main comparison is between JAX and Autograd, as the utility of JAX/Autograd is not directly comparable to the purpose of PyTorch/TensorFlow. PyTorch and Tensorflow are dedicated deep learning libraries with a lot of high-level APIs for state-of-the-art methods in deep learning, while JAX and Autograd are more functionally-minded libraries for arbitrary differentiable programming. We discussed differentiable programming, how it is a generalized concept that encompasses deep learning and more, and some of the awesome projects differentiable programming is being used for in a previous article.
You can expect some speedup over Autograd or native NumPy simply by dropping in JAX’s version of NumPy and using JAX functions where possible (e.g. for common neural network operations like dense layers). JAX uses just-in-time compilation for library calls, but you can also use the jit function transformation as a decorator for custom Python functions, or as a function with the original function as argument. Here are examples of both methods:
<table><tbody><tr><td># use jit as a decorator on a function definition<p></p>
<p>@jit</p>
<p>def get_loss(x, w, y_tgts):</p>
<p> y_pred = forward(x, w)</p>
<p> return ce_loss(y_tgts, y_pred)</p>
<p># use jit as a function for transforming an already defined function into a just-in-time compiled function</p>
<p>get_grad = grad(get_loss, argnums=(1))</p>
<p>jit_grad = jit(get_grad)</p></td></tr></tbody></table>To compare execution times, we implemented an exceedingly simple multi layer perceptron (MLP) with each library. This MLP has one hidden layer and a non-linear activation function, the simplest configuration that still meets the requirements of the universal approximation theorem. In short it’s a sequence of numerical values determined by weighted connections, conveniently equivalent to the matrix multiplication of input tensors and weight matrices.
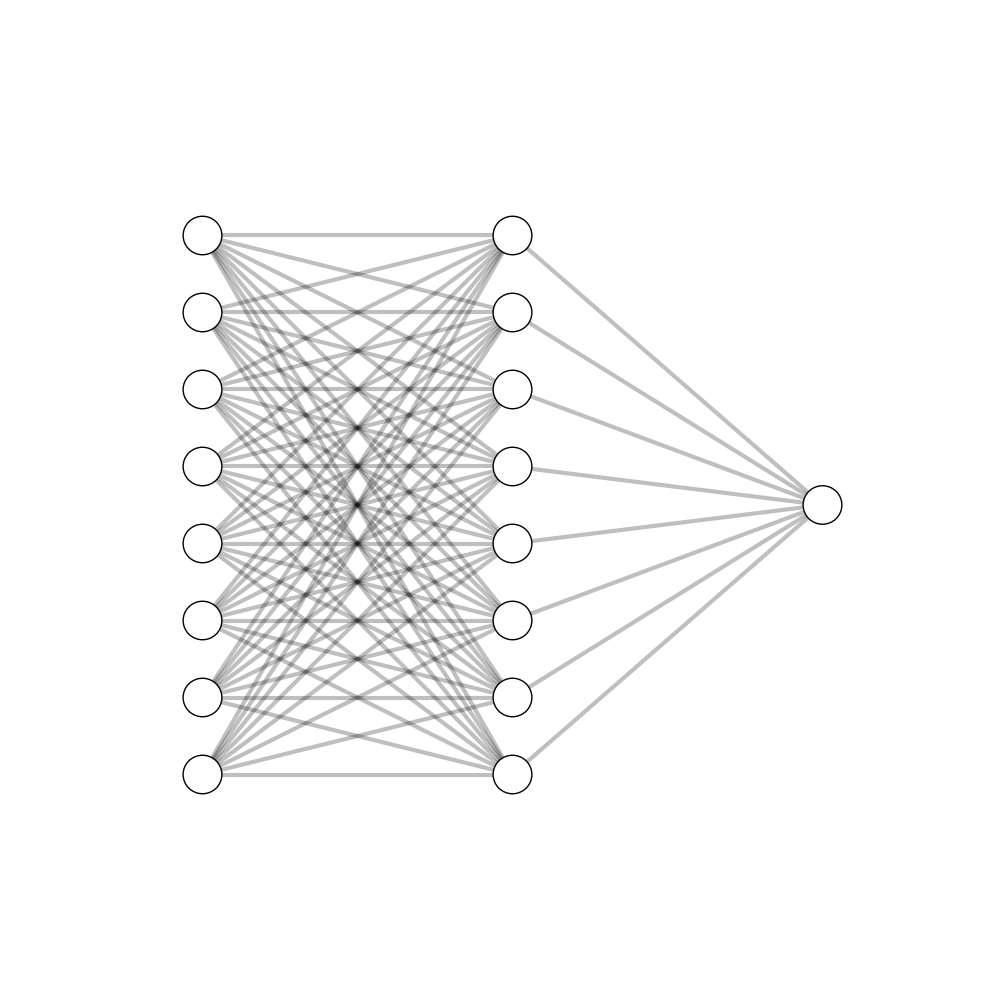
A simple MLP with one hidden layer.
We intended to implement each MLP using only the low-level primitive of matrix multiplication to keep things standardized and to more accurately reflect the ability of each library to perform automatic differentiation over arbitrary computations, instead of comparing the efficacy of higher-level API calls available in the dedicated deep learning libraries PyTorch and TensorFlow. However, we ran into some problems performing automatic differentiation over matrix multiplication in PyTorch after sending the weight tensors to a GPU,, so we decided to make a second implementation in PyTorch using the torch.nn.Sequential and torch.nn.Linear API. To keep things moderately fair, we did the same for TensorFlow by creating a second MLP implementation with tf.keras.models.Sequential and tf.keras.layers.Dense. JAX also offers some experimental functionality for describing neural networks at a higher level in jax.experimental.stax.Dense, but we won’t investigate that here.
This runtime comparison was made on a relatively old and underpowered workstation running Ubuntu 18.04 on an Intel Core i3 dual core 3.7 GHz CPU and a single Nvidia GTX 1060 GPU with 6GB of memory. If you’d like to replicate the experiment on your own machine, you’ll find the code in the following Github repository:
| git clone https://github.com/riveSunder/MLPDialects.git
cd MLPDialects |
To keep the different libraries isolated, we recommend using Python’s virtual environment functionality (sudo apt-get install -y virtualenv on Debian-based systems), but feel free to adjust the instructions below to use another choice of virtual environment manager like conda. If you just want to see the results, skip ahead to the next section.
| virtualenv autograd_env –python=python3
source autograd_env/bin/activate pip install autograd # run the experiment python ag_nn2.py |
| # CPU only
virtualenv tf_cpu_env –python=python3 source tf_cpu_env/bin/activate pip install tensorflow==2.0 # run the experiment python tf_nn2.py # TensorFlow with GPU virtualenv tf_gpu_env –python=python3 source tf_gpu_env/bin/activate pip install tensorflow-gpu==2.0 # run the experiment (matmul) python tf_nn2.py # run the experiment (Dense) python tf_gpu_nn.py |
| virtualenv torch_env –python=python3
source torch_env/bin/activate pip install torch # run the experiment (matmul on CPU) python torch_nn2.py # run the experiment (Linear on GPU) python torch_gpu_nn.py |
| # CPU only
virtualenv jax_env –python=python3 source jax_env/bin/activate pip install jax jaxlib # run the experiment (matmul on CPU) python jax_nn2.py |
The installation of JAX with GPU support will depend on how your system is set up, notably your CUDA and Python version. Follow the instructions on the JAX repository README to install JAX with GPU support, then run python jax_nn2.py.
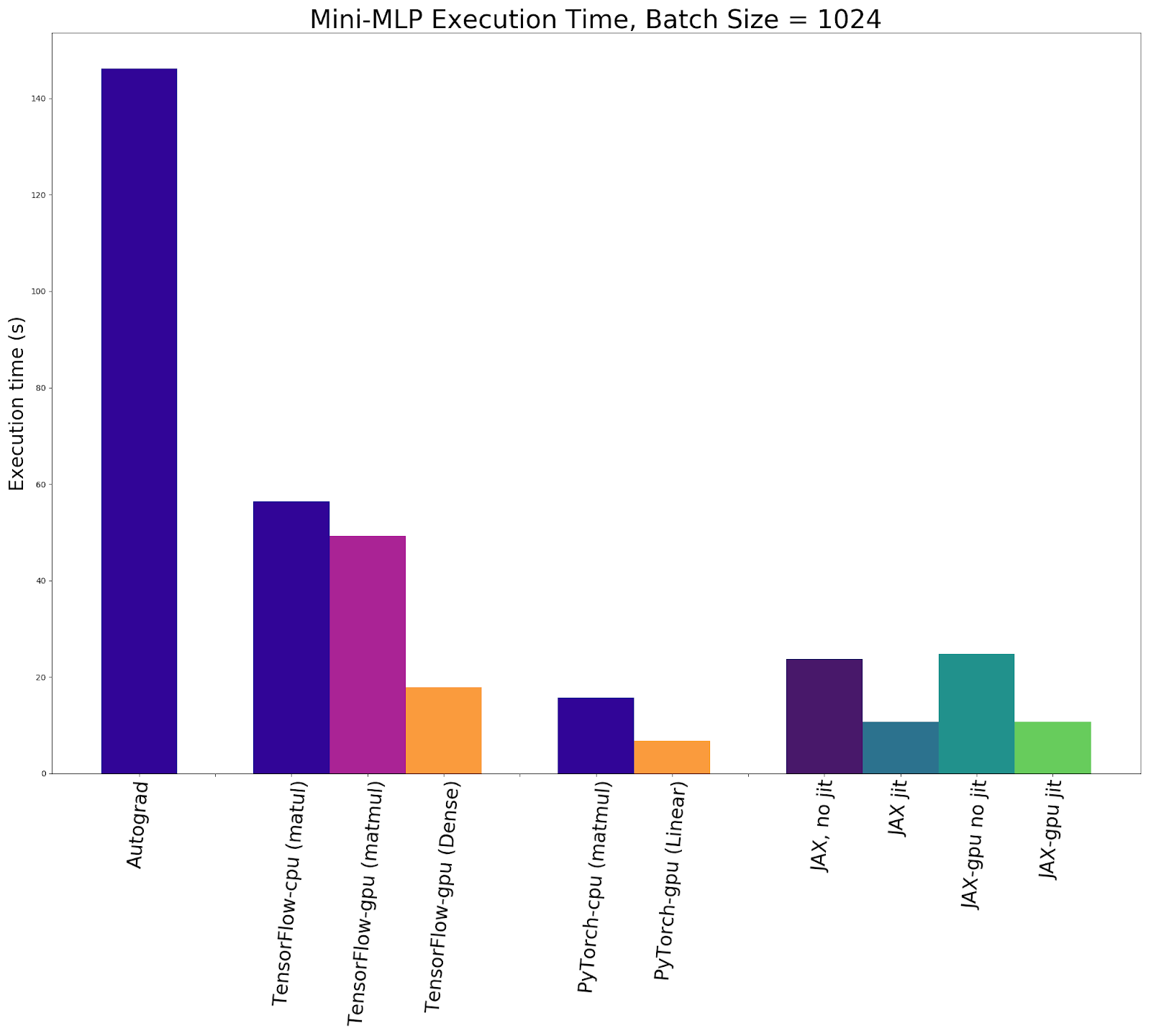
Execution times for 10,000 updates with a batch size of 1024.
Unsurprisingly, JAX is substantially faster than Autograd at executing a 10,000 step training loop, with or without just-in-time compilation. What’s more surprising is that JAX is incredibly competitive against both TensorFlow and PyTorch, at least with the small model size and matmul implementation used in the experiment. JAX with JIT had a faster CPU execution time than any other library, and the fastest execution time for implementations using only matrix multiplication. Running on the GPU, PyTorch had an exceedingly quick execution time using torch.nn.Linear, achieving a best overall execution time of about 6 seconds regardless of whether a batch size of 1024 or 4096 was used, In fact, even a batch size of 16384 took 9.9 seconds with PyTorch and Linear layers, about the same as JAX running with JIT on a batch size of 1024.
| Library Used (10,000 steps with a batch size of 1024) | Execution Time (s) | Normalized to “JAX-GPU w/ jit”
(nearest 0.1) |
| Autograd | 146.23 | 13.6 |
| TensorFlow-CPU (matmul) | 56.4 | 5.2 |
| TensorFlow-GPU (matmul) | 49.52 | 4.6 |
| TensorFlow-GPU (Dense)* | 17.89 | 17.8 |
| PyTorch-CPU (matmul) | 15.73 | 1.5 |
| PyTorch-GPU (Linear)* | 6.81 | 0.6 |
| JAX-CPU w/0 jit | 23.68 | 2.2 |
| JAX-CPU w/ jit | 10.73 | 1.0 |
| JAX-GPU w/o jit | 24.81 | 2.3 |
| JAX-GPU w/ jit | 10.77 | 1.0 |
Execution times for 10,000 updates with batch size of 4,096. *Implementations utilized higher level neural network layer calls.
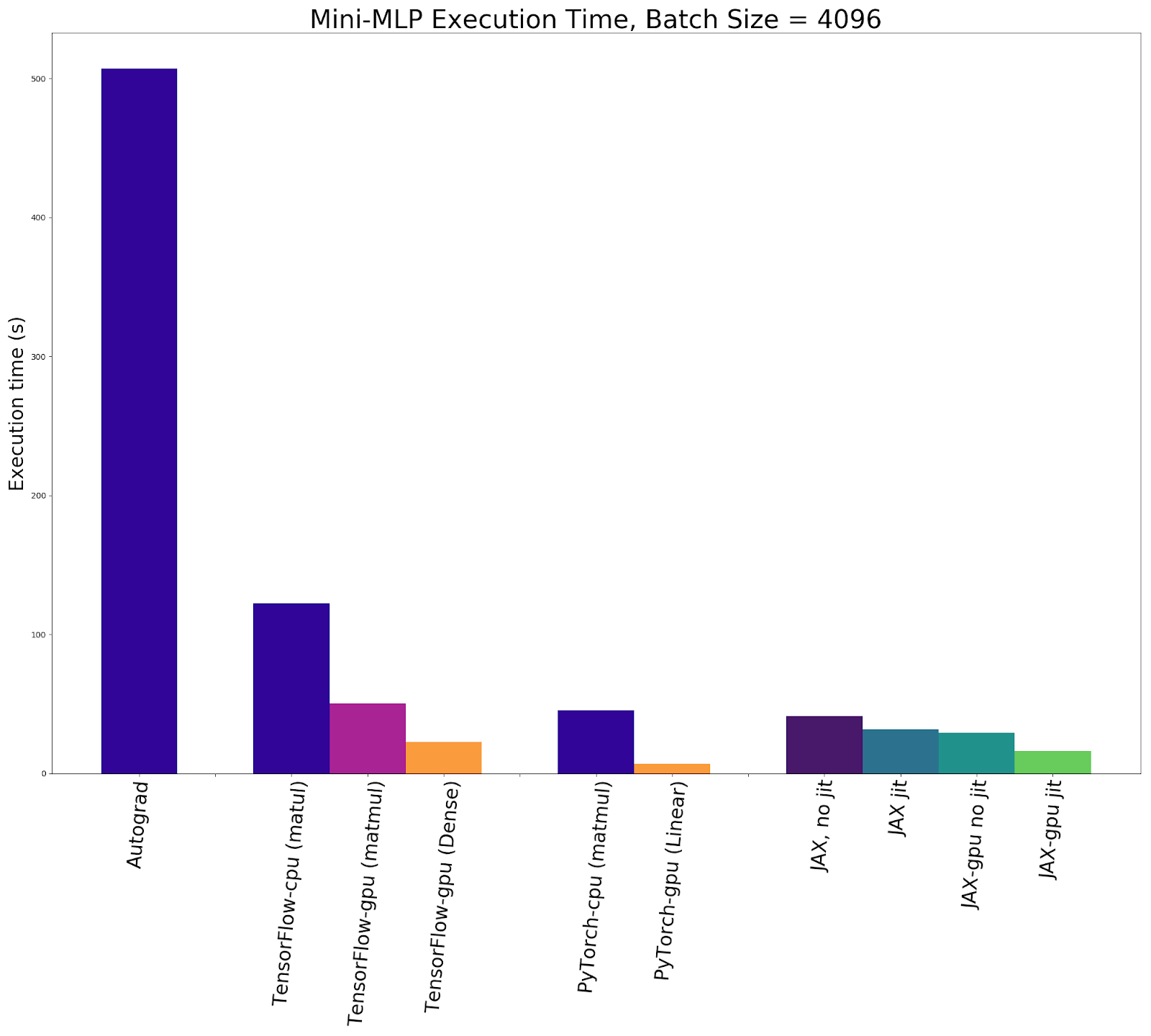
The results essentially stayed the same when we re-ran the experiment with a batch size of 4096. If we restrict our consideration to only MLP implementations using matrix multiplication, JAX was again faster than any other library, often by a significant margin. This time JAX with JIT compilation running on the GPU was also twice as fast as JIT-compiled JAX running on the CPU, unlike the experiment with a sample size of 1024 where CPU and GPU execution was about the same with JAX.
Interested in getting faster results?
Learn more about Exxact Deep Learning Solutions
If we expand our consideration to include implementations taking advantage of higher-level neural network APIs available in TensorFlow and PyTorch, TensorFlow was still significantly slower than JAX but PyTorch was by far the fastest. There was little difference between the GPU MLP implementation written in PyTorch for a batch size of 1024 or 4096, indicating there are still substantial improvements left on the table to be achieved by increasing the batch size further.
| Library Used (10,000 steps with a batch size of 4096) | Execution Time (s) | Normalized to “JAX-GPU w/ jit”
(nearest 0.1) |
| Autograd | 507.39 | 31.9 |
| TensorFlow-CPU (matmul) | 122.34 | 7.7 |
| TensorFlow-GPU (matmul) | 50.30 | 3.2 |
| TensorFlow-GPU (Dense)* | 22.84 | 1.4 |
| PyTorch-CPU (matmul) | 45.44 | 2.9 |
| PyTorch-GPU (Linear)* | 6.79 | 0.4 |
| JAX-CPU w/0 jit | 41.24 | 2.6 |
| JAX-CPU w/ jit | 31.77 | 2.0 |
| JAX-GPU w/o jit | 29.51 | 1.9 |
| JAX-GPU w/ jit | 15.92 | 1.0 |
Execution times for 10,000 updates with batch size of 4,096. *Implementations utilized higher level neural network layer calls.
The results of this small experiment are pretty clear: neuro-centric projects are likely to benefit substantially from taking advantage of optimized implementations of higher-level functions in deep learning-specific libraries.
Surprisingly, PyTorch was much more effective in terms of execution speed than TensorFlow when it came to implementing fully-connected neural layers, but we did not consider other essential deep learning operations like convolution, max-pooling, batch normalization, etc.
For low-level implementations, on the other hand, JAX offers impressive speed-ups of an order of magnitude or more over the comparable Autograd library. JAX also was faster than any other library when MLP implementation was limited to matrix multiplication operations.
Your choice of machine learning library will likely depend on the project context. If your team always uses TensorFlow for everything, you’ll probably end up writing and debugging a lot of code in TensorFlow. If you have the flexibility to influence design decisions when planning a new project, hopefully this article has given you some useful information to consider. The differences in execution time we saw in the simple experiment explored in this post are significant enough to warrant running a similar experiment before committing to use a specific library.
Although we looked at models based only on matrix multiplication today, it won’t hurt to make some back-of-the-envelope calculations of what mathematical primitives are likely to be called the most in your project, and run a scaled-down experiment to determine which library is best-suited for your purpose.
For general differentiable programming with low-level implementations of abstract mathematical concepts, JAX offers substantial advantages in speed and scale over Autograd while retaining much of Autograd’s simplicity and flexibility, while also offering surprisingly competitive performance against PyTorch and TensorFlow.

Have any questions about machine learning libraries or systems that can support them?
Contact Exxact Today
Featured image from photographers Austin Kirk and Adam R on Pixabay.
Automatic differentiation underlies the vast majority of success in modern deep learning. This makes a big difference in development time for researchers iterating over models and experiments. Before widely available tools for automatic differentiation, programmers had to “roll their own” gradients, which is not only time-consuming but introduces a substantial coding surface that increases the probability of accumulating disastrous bugs.
Libraries like the well-known TensorFlow and PyTorch keep track of gradients over neural network parameters during training, and they each contain high-level APIs for implementing the most commonly used neural network functionality for deep learning. While this is ideal for production and scaling models to deployment, it leaves something to be desired if you want to build something a little off the beaten path. Autograd is a versatile library for automatic differentiation of native Python and NumPy code, and it’s ideal for combining automatic differentiation with low-level implementations of mathematical concepts to build not only new models, but new types of models (including hybrid physics and neural-based learning models).
While it is a flexible library with an inviting learning curve (NumPy users can jump in at the deep end), Autograd is no longer under active development and it tends to be too slow for medium to large-scale experiments. Development for running Autograd on GPUs was never completed, and therefore training is limited by the execution time of native NumPy code. Consequently JAX is a better choice of automatic differentiation libraries for many serious projects, thanks to just-in-time compilation and support for hardware acceleration.
JAX is the immediate successor to the Autograd library: all four of the main developers of Autograd have contributed to JAX, with two of them working on it full-time at Google Brain. JAX is a Python library that combines hardware acceleration and automatic differentiation with XLA, compiled instructions for faster linear algebra methods, often with improvements to memory usage as well. JAX utilizes the grad function transformation to convert a function into a function that returns the original function’s gradient, just like Autograd. Beyond that, JAX offers a function transformation jit for just-in-time compilation of existing functions and vmap and pmap for vectorization and parallelization, respectively. JAX also will run your models on a GPU (or TPU) if available.
We implemented a simple, single-hidden layer MLP in JAX, Autograd, Tensorflow 2.0 and PyTorch, along with a training loop to “fit” a classification problem of random noise. We tried to implement these all in the same style with a low-level implementation based on matrix multiplies, but you’ll see that we had to take a few shortcuts to implement the model in PyTorch with GPU support.
These implementations provide a baseline for comparing the performance efficiency of each library, although our main comparison is between JAX and Autograd, as the utility of JAX/Autograd is not directly comparable to the purpose of PyTorch/TensorFlow. PyTorch and Tensorflow are dedicated deep learning libraries with a lot of high-level APIs for state-of-the-art methods in deep learning, while JAX and Autograd are more functionally-minded libraries for arbitrary differentiable programming. We discussed differentiable programming, how it is a generalized concept that encompasses deep learning and more, and some of the awesome projects differentiable programming is being used for in a previous article.
You can expect some speedup over Autograd or native NumPy simply by dropping in JAX’s version of NumPy and using JAX functions where possible (e.g. for common neural network operations like dense layers). JAX uses just-in-time compilation for library calls, but you can also use the jit function transformation as a decorator for custom Python functions, or as a function with the original function as argument. Here are examples of both methods:
<table><tbody><tr><td># use jit as a decorator on a function definition<p></p>
<p>@jit</p>
<p>def get_loss(x, w, y_tgts):</p>
<p> y_pred = forward(x, w)</p>
<p> return ce_loss(y_tgts, y_pred)</p>
<p># use jit as a function for transforming an already defined function into a just-in-time compiled function</p>
<p>get_grad = grad(get_loss, argnums=(1))</p>
<p>jit_grad = jit(get_grad)</p></td></tr></tbody></table>To compare execution times, we implemented an exceedingly simple multi layer perceptron (MLP) with each library. This MLP has one hidden layer and a non-linear activation function, the simplest configuration that still meets the requirements of the universal approximation theorem. In short it’s a sequence of numerical values determined by weighted connections, conveniently equivalent to the matrix multiplication of input tensors and weight matrices.
A simple MLP with one hidden layer.
We intended to implement each MLP using only the low-level primitive of matrix multiplication to keep things standardized and to more accurately reflect the ability of each library to perform automatic differentiation over arbitrary computations, instead of comparing the efficacy of higher-level API calls available in the dedicated deep learning libraries PyTorch and TensorFlow. However, we ran into some problems performing automatic differentiation over matrix multiplication in PyTorch after sending the weight tensors to a GPU,, so we decided to make a second implementation in PyTorch using the torch.nn.Sequential and torch.nn.Linear API. To keep things moderately fair, we did the same for TensorFlow by creating a second MLP implementation with tf.keras.models.Sequential and tf.keras.layers.Dense. JAX also offers some experimental functionality for describing neural networks at a higher level in jax.experimental.stax.Dense, but we won’t investigate that here.
This runtime comparison was made on a relatively old and underpowered workstation running Ubuntu 18.04 on an Intel Core i3 dual core 3.7 GHz CPU and a single Nvidia GTX 1060 GPU with 6GB of memory. If you’d like to replicate the experiment on your own machine, you’ll find the code in the following Github repository:
| git clone https://github.com/riveSunder/MLPDialects.git
cd MLPDialects |
To keep the different libraries isolated, we recommend using Python’s virtual environment functionality (sudo apt-get install -y virtualenv on Debian-based systems), but feel free to adjust the instructions below to use another choice of virtual environment manager like conda. If you just want to see the results, skip ahead to the next section.
| virtualenv autograd_env –python=python3
source autograd_env/bin/activate pip install autograd # run the experiment python ag_nn2.py |
| # CPU only
virtualenv tf_cpu_env –python=python3 source tf_cpu_env/bin/activate pip install tensorflow==2.0 # run the experiment python tf_nn2.py # TensorFlow with GPU virtualenv tf_gpu_env –python=python3 source tf_gpu_env/bin/activate pip install tensorflow-gpu==2.0 # run the experiment (matmul) python tf_nn2.py # run the experiment (Dense) python tf_gpu_nn.py |
| virtualenv torch_env –python=python3
source torch_env/bin/activate pip install torch # run the experiment (matmul on CPU) python torch_nn2.py # run the experiment (Linear on GPU) python torch_gpu_nn.py |
| # CPU only
virtualenv jax_env –python=python3 source jax_env/bin/activate pip install jax jaxlib # run the experiment (matmul on CPU) python jax_nn2.py |
The installation of JAX with GPU support will depend on how your system is set up, notably your CUDA and Python version. Follow the instructions on the JAX repository README to install JAX with GPU support, then run python jax_nn2.py.
Execution times for 10,000 updates with a batch size of 1024.
Unsurprisingly, JAX is substantially faster than Autograd at executing a 10,000 step training loop, with or without just-in-time compilation. What’s more surprising is that JAX is incredibly competitive against both TensorFlow and PyTorch, at least with the small model size and matmul implementation used in the experiment. JAX with JIT had a faster CPU execution time than any other library, and the fastest execution time for implementations using only matrix multiplication. Running on the GPU, PyTorch had an exceedingly quick execution time using torch.nn.Linear, achieving a best overall execution time of about 6 seconds regardless of whether a batch size of 1024 or 4096 was used, In fact, even a batch size of 16384 took 9.9 seconds with PyTorch and Linear layers, about the same as JAX running with JIT on a batch size of 1024.
| Library Used (10,000 steps with a batch size of 1024) | Execution Time (s) | Normalized to “JAX-GPU w/ jit”
(nearest 0.1) |
| Autograd | 146.23 | 13.6 |
| TensorFlow-CPU (matmul) | 56.4 | 5.2 |
| TensorFlow-GPU (matmul) | 49.52 | 4.6 |
| TensorFlow-GPU (Dense)* | 17.89 | 17.8 |
| PyTorch-CPU (matmul) | 15.73 | 1.5 |
| PyTorch-GPU (Linear)* | 6.81 | 0.6 |
| JAX-CPU w/0 jit | 23.68 | 2.2 |
| JAX-CPU w/ jit | 10.73 | 1.0 |
| JAX-GPU w/o jit | 24.81 | 2.3 |
| JAX-GPU w/ jit | 10.77 | 1.0 |
Execution times for 10,000 updates with batch size of 4,096. *Implementations utilized higher level neural network layer calls.
The results essentially stayed the same when we re-ran the experiment with a batch size of 4096. If we restrict our consideration to only MLP implementations using matrix multiplication, JAX was again faster than any other library, often by a significant margin. This time JAX with JIT compilation running on the GPU was also twice as fast as JIT-compiled JAX running on the CPU, unlike the experiment with a sample size of 1024 where CPU and GPU execution was about the same with JAX.
Interested in getting faster results?
Learn more about Exxact Deep Learning Solutions
If we expand our consideration to include implementations taking advantage of higher-level neural network APIs available in TensorFlow and PyTorch, TensorFlow was still significantly slower than JAX but PyTorch was by far the fastest. There was little difference between the GPU MLP implementation written in PyTorch for a batch size of 1024 or 4096, indicating there are still substantial improvements left on the table to be achieved by increasing the batch size further.
| Library Used (10,000 steps with a batch size of 4096) | Execution Time (s) | Normalized to “JAX-GPU w/ jit”
(nearest 0.1) |
| Autograd | 507.39 | 31.9 |
| TensorFlow-CPU (matmul) | 122.34 | 7.7 |
| TensorFlow-GPU (matmul) | 50.30 | 3.2 |
| TensorFlow-GPU (Dense)* | 22.84 | 1.4 |
| PyTorch-CPU (matmul) | 45.44 | 2.9 |
| PyTorch-GPU (Linear)* | 6.79 | 0.4 |
| JAX-CPU w/0 jit | 41.24 | 2.6 |
| JAX-CPU w/ jit | 31.77 | 2.0 |
| JAX-GPU w/o jit | 29.51 | 1.9 |
| JAX-GPU w/ jit | 15.92 | 1.0 |
Execution times for 10,000 updates with batch size of 4,096. *Implementations utilized higher level neural network layer calls.
The results of this small experiment are pretty clear: neuro-centric projects are likely to benefit substantially from taking advantage of optimized implementations of higher-level functions in deep learning-specific libraries.
Surprisingly, PyTorch was much more effective in terms of execution speed than TensorFlow when it came to implementing fully-connected neural layers, but we did not consider other essential deep learning operations like convolution, max-pooling, batch normalization, etc.
For low-level implementations, on the other hand, JAX offers impressive speed-ups of an order of magnitude or more over the comparable Autograd library. JAX also was faster than any other library when MLP implementation was limited to matrix multiplication operations.
Your choice of machine learning library will likely depend on the project context. If your team always uses TensorFlow for everything, you’ll probably end up writing and debugging a lot of code in TensorFlow. If you have the flexibility to influence design decisions when planning a new project, hopefully this article has given you some useful information to consider. The differences in execution time we saw in the simple experiment explored in this post are significant enough to warrant running a similar experiment before committing to use a specific library.
Although we looked at models based only on matrix multiplication today, it won’t hurt to make some back-of-the-envelope calculations of what mathematical primitives are likely to be called the most in your project, and run a scaled-down experiment to determine which library is best-suited for your purpose.
For general differentiable programming with low-level implementations of abstract mathematical concepts, JAX offers substantial advantages in speed and scale over Autograd while retaining much of Autograd’s simplicity and flexibility, while also offering surprisingly competitive performance against PyTorch and TensorFlow.
Have any questions about machine learning libraries or systems that can support them?
Contact Exxact Today



