Deep Learning
6 Critical Components Every Deep Learning System Needs and Aspects to Consider
October 1, 2019
18 min read


Many people deal with the question of whether to purchase their own Deep Learning system for on-premises use. While some people are content with cloud-based solutions that offer computing time, there are very valid points that favor an on-premises solution. Once the decision has been made, however, what comes next? Are the solutions simple and ready-made with few options, or do the specific components require research and consideration? The short answer is that any serious investment demands that due diligence be exercised, and purchasing a Deep Learning system is no exception.
Putting together your own Deep Learning system is an exciting prospect. At the same time, with so many options to consider, coming up with a system to do what you want, within budget, can be a little daunting. In this article, we cover the main components that are critical for every Deep Learning system, and what you need to know to make the choices that best suit your needs.

The upfront cost of putting together your own Deep Learning machine is significant and is directly related to the components that you select. Each of the components discussed here come in several varieties, and one of the obvious differences is the price. Not unlike most products, as capability increases, so does the purchase price.
It is a good idea to have a budget in mind and do your best to stick to it. Last-minute changes and upgrades are acceptable, but striving for the best-in-class of each and every component may be a very costly endeavor that is unrealistic for some.
The type of Deep Learning system that you need will depend on the types of tasks that you want to perform. In cases, for example, where there are small amounts of data and lots of computations that need to be made, raw processing power will be a priority over larger and faster storage. Conversely, if there is a lot of data that has to be constantly referenced for training models, then large amounts of on-board memory, or RAM, may be necessary to train at a reasonable speed.
The system that you put together now may very well suit your needs into the future, but for how long? Upgrading or adding new components to your Deep Learning system is a great way to extend its life, and having an expandable system is a good measure of flexibility.
The distinction between upgrading and expanding is simple. If a part is being replaced with one that is more powerful then that is an upgrade. If something new is being added then it is an expansion. For example, replacing an older CPU with a newer, faster one, is a nice upgrade for a single-CPU motherboard that is flexible enough to support the newer processor. Conversely, putting additional memory into vacant slots to add to the total on-board memory size is, there you have it -- expansion. Having those extra slots on the motherboard is one example of expansion and being expandable.
When it comes to technology, support is an important thing to consider. For the most part, you will not have to worry about troubleshooting components in your Deep Learning machine. If something goes wrong then it will be repaired by an authorized technician, or replaced. The type of support relevant to the task at hand is related to usability. Essentially, you want to use components that are well supported by the manufacturer.
A good example of this are GPUs, where NVIDIA GPUs are more widely supported than those by other manufacturers. This leads to more developers writing better libraries and applications, ultimately making NVIDIA a better choice for your Deep Learning system.
While some enthusiasts recommend purchasing components separately, over time, this is not the type of advice that best suits everybody. An important factor that some overlook is the total time it takes, from start to completion, to build your system. Proponents of this strategy suggest watching the marketplace for sales, or otherwise good deals, on specific parts and purchasing them at the right time. There are at least two closely related problems with this plan.
The first is that you may not be able to test the individual components as they arrive because they are interdependent. In a perfect world, everything that you purchase will work perfectly out of the box. However, most of us know from experience that dead-on-arrival (DOA) parts arrive often enough that testing within the DOA period is important. In particular, with “open box” or refurbished parts, making sure that they function correctly is critical. The problem is that if there are too few parts to create even a barebones system then testing an individual component requires the use of a second, working system. If you don’t have one, or at least have access to one, then the new arrival has to sit on the shelf until you’re ready for it.
The second problem follows directly from the first, and it concerns the general warranty. Assuming that you are able to test the new component are verify that it’s functioning to specification, if it doesn’t have a permanent home then again, it sits on the shelf. This may not seem like a problem for something like a brand new NVIDIA Video Card with a three-year warranty, but for clearance or “open box” items, it may very well be relevant.
The bottom line is that length of time from the purchase of the first component, up until the system is built and tested, matters. In an extreme example, you don’t want several components to be out of warranty before they are even turned on.
Interested in your own pre-built deep learning system? Our Exxact Valence Workstation offers everything you need to get started to accelerate your deep learning training. Experience the power of NVIDIA GPUs, featuring selections from the RTX 2080 Ti, TITAN RTX, Quadro RTX 6000, and more. Also pre-installed with the latest deep learning frameworks including TensorFlow, PyTorch, Keras, and more!
Keeping in mind the various aspect listed above, it is now time to put some thought into the components, themselves.
The motherboard is the first option in this list because everything else plugs into it. However, it might more appropriately be placed at the end because it has to be the one piece that is compatible with everything else.
Your choice of motherboard is directly tied to which components are compatible with your system, and more importantly, how scalable, or expandable it is. Motherboards come in different form factors, where a smaller size might be easier to fit on your desk, but a lot less expandable than a larger one (e.g. MBD-C7B75-B vs MBD-X10DAC-B).
Your choice of motherboard will set the upper limit for the number of CPUs, GPUs, available memory slots, maximum supported memory, and PCI Express expansion slots. Similarly, different motherboards are only compatible with certain components such as specific CPUs and types of memory modules.
Once your motherboard has been chosen, the number of options narrows. If it is the first component that you choose then be sure to check for compatibility at each step of the way
The Graphics Processing Unit is the heart of every Deep Learning system. Regardless of the problem you’re tackling, your choice of GPU type and configuration drive the speed of your work. The first decision is the number of GPUs.
Trivially, a single-GPU system is a more cost-effective solution, and perhaps suitable for somebody who is not fully committed. Moving beyond this, a dual-GPU or multi-GPU system will allow you to run many different problems, or perhaps the same problem with many different hyper-parameter settings, in parallel. For a machine learning researcher, the ability to run experiments in parallel makes the multi-GPU system a wise investment.
Once the number of GPUs is set, the brand and model are the next things to be considered. Largely, your choice of GPU will come down to price and support. For the heart of your system, you want the best GPU that fits within your budget, with the maximum usability of third-party libraries and applications.
List of NVIDIA Turing GPUs we recommend for a deep learning system:
In the link above, we compared the 4 different types of GPUs and how they stack up for specific deep learning applications, Computer Vision and Natural Language Processing (NLP). Consider the following GPUs for NLP, where modern architectures require a large GPU memory pool to achieve best results.
BLEU Score (NLP Metric)
Here we compare training the official Transformer model (BASE and BIG) from the official TensorFlow GitHub.
| Transformer BLEU Score trained with RTX 6000 (BIG Model) | Transformer BLEU Score trained with RTX 2080 ti (BASE Model) |
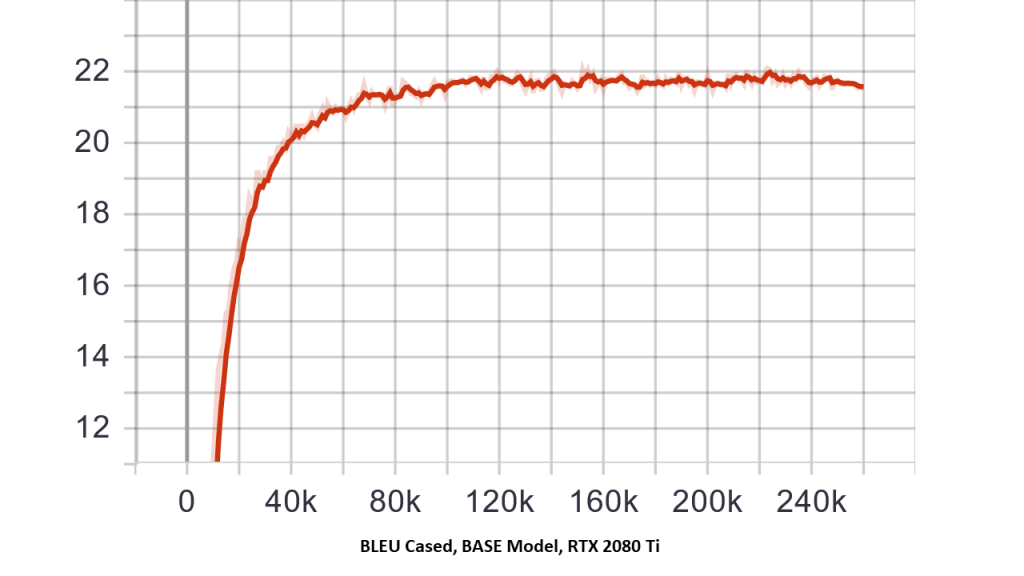
| The Big model trained using the RTX 6000 can obtain a higher bleu score (based on vanilla settings for transformer model). Default settings/batch size were used on 2x RTX 6000 wNVLink system. | Here, the BASE model trained using the RTX 2080 Ti (based on vanilla settings for transformer model) clearly is inferior. Note: BIG model failed training on 2x 2080 Ti System with default batch size. |

|  |

The Central Processing Unit may not be the computational workhorse in a Deep Learning system, but its role is important nonetheless. The job of the CPU in this situation is to handle data transport. Whether your data resides in memory or in external storage, it needs to be retrieved and supplied to the GPU. Then once the GPU has completed the necessary calculations, the results have to be moved to memory and perhaps, a hard drive or solid-state drive. If the storage is across a network, then the CPU will be responsible for communicating with the network components to supply data to and from the GPU. Essentially, it handles everything except the specific calculations that the GPU is very good at.
With myriad CPU choices, how do you know what best fits your requirements? As already mentioned, if the choice of motherboard has been made then it narrows the options. Even so, there will be factors such as clock rate, the number of PCIe lanes, and the number of cores that need to be considered.
Clock Rate
Generally speaking, the clock rate refers to how fast the CPU operates, and in a single-core CPU it is directly related to the number of instructions it can perform per second. The clock rate is not as useful for comparing CPUs from different manufacturers, but it is a common measure regardless. The next thing to consider is the maximum number of PCIe lanes.
PCIe Lanes
While the CPU is responsible for supplying data to the GPU for processing, a PCIe lane is the method of transport. The number of PCIe lanes is dependent on both the motherboard and the CPU. Often, technicians will refer to the motherboard chipset, which will have support for a maximum number of PCIe lanes. The demand, however, comes from the number of GPUs. In theory, there is a potential bottleneck in data transport unless there are 16 PCIe lines per GPU in your system.
Number of cores
In a multi-core CPU, each core can handle additional operations being executed in parallel, thus increasing the total number of instructions per second. The real question is whether this is relevant to a Deep Learning system. The answer is yes, it is.
The CPU handles the data processing in parallel with the GPU performing its own tasks. When the GPU finishes it becomes idle until the next block of data arrives, and you’ll want to minimize that downtime as much as practical. A good rule of thumb is to have two cores per GPU, so a dual-GPU system should be supported by a CPU with four cores.
When it comes to memory there are a few things to consider. The total amount of memory will dictate how much data you can load at one time. For building models, the more training data that can fit into memory, the better. Having to retrieve data from external storage is significantly slower, so for cases with lots of data, you want lots of RAM to avoid unnecessary disk accesses. At a minimum, you want to have at least as much memory in the system as there is with the largest GPU, otherwise, a potential bottleneck arises. This means that if your GPU has 32 GB then the minimum RAM you should have is 32 GB.
The form factor should also be considered, in conjunction with the number of memory slots on the motherboard, to help plan for expansion. For example, in the aforementioned 32 GB example, it would be more scalable to use two 16 GB memory modules compared to four 8 GB modules because it leaves two open slots for future expansion.
With respect to the RAM speed, the higher the better. Again, a rise in cost is typical as the speed of memory increases, so your budget will be affected accordingly.
Storage for your Deep Learning system comes in two varieties: Hard drives (HDDs) and Solid-state drives (SSDs). The traditional HDD is a cheaper, albeit slower, storage facility than an SSD. Current day systems use a combination of storage devices, with an SSD to host the operating system and frequently used files, and the HDD to store the bulk of user data and applications. A similar approach can be used for your Deep Learning system, with the SSD also being used to store active training sets.
When it comes to pricing for storage, there is always an optimal purchase point where you get the best bang for the buck. Beyond a certain threshold, you are paying far too much for a resource that is easily upgraded at a later point. Pricing for storage changes frequently, so rather than make specific suggestions, it is better to specify the minimum requirements. Budget permitting, an SSD that is between 128 GB and 256 GB is a reasonable size for the operating system and active datasets, whereas a 2 TB HDD has plenty of room for applications, a development environment, datasets, models, results, and reports.
On the topic of scalability, motherboards generally have support for several storage devices, but again, this is an option. Look for things like the number of SATA interfaces, and even the number of USB interfaces for supporting storage devices outside of the case.
Computer Power Supply Units are used to convert power from the outlet into power that is usable by the components inside the case. PSUs are rated by their wattage, so when people talk about having a bigger power supply, it normally refers to one that supplies a higher number of watts. Your choice of power supply depends on the combination of your components, being careful to leave room for expansion in the future. It is a good practice to buy one that is slightly larger than required because the only downside to having a larger PSU is the initial cost.
The Outervision Power Supply Calculator is a useful resource to help determine what size of PSU you need. There are other considerations, such as how energy efficient or noisy they are, but these options are not as important as having the power required to run your system.
Having your own Deep Learning system is a great investment that will serve your projects well, and save you money in the long run. As with any investment, there are various things to consider, and the total cost is not the least of them. Once the initial planning is complete, it is time to select the components.
Purchasing all of the necessary parts can be done at one time, or it can be spread out to make the experience more budget-friendly. However, be wary of warranties and the possibility of faulty parts that could remain untested during the construction phase.
There are numerous options for each of the critical components. Some of these are dependent on the others, so double-checking for compatibility at every step of the way is highly recommended. Similarly, the complete system should consist of parts that best suit your needs, and the requirements of the projects that you want to tackle. This means being mindful of well-supported products that have a proven record of getting work done.
Ideally, once your system is built and you’ve given it some large tasks leading to great results, it’s flexible enough to upgrade and expand to the next level.

Many people deal with the question of whether to purchase their own Deep Learning system for on-premises use. While some people are content with cloud-based solutions that offer computing time, there are very valid points that favor an on-premises solution. Once the decision has been made, however, what comes next? Are the solutions simple and ready-made with few options, or do the specific components require research and consideration? The short answer is that any serious investment demands that due diligence be exercised, and purchasing a Deep Learning system is no exception.
Putting together your own Deep Learning system is an exciting prospect. At the same time, with so many options to consider, coming up with a system to do what you want, within budget, can be a little daunting. In this article, we cover the main components that are critical for every Deep Learning system, and what you need to know to make the choices that best suit your needs.
The upfront cost of putting together your own Deep Learning machine is significant and is directly related to the components that you select. Each of the components discussed here come in several varieties, and one of the obvious differences is the price. Not unlike most products, as capability increases, so does the purchase price.
It is a good idea to have a budget in mind and do your best to stick to it. Last-minute changes and upgrades are acceptable, but striving for the best-in-class of each and every component may be a very costly endeavor that is unrealistic for some.
The type of Deep Learning system that you need will depend on the types of tasks that you want to perform. In cases, for example, where there are small amounts of data and lots of computations that need to be made, raw processing power will be a priority over larger and faster storage. Conversely, if there is a lot of data that has to be constantly referenced for training models, then large amounts of on-board memory, or RAM, may be necessary to train at a reasonable speed.
The system that you put together now may very well suit your needs into the future, but for how long? Upgrading or adding new components to your Deep Learning system is a great way to extend its life, and having an expandable system is a good measure of flexibility.
The distinction between upgrading and expanding is simple. If a part is being replaced with one that is more powerful then that is an upgrade. If something new is being added then it is an expansion. For example, replacing an older CPU with a newer, faster one, is a nice upgrade for a single-CPU motherboard that is flexible enough to support the newer processor. Conversely, putting additional memory into vacant slots to add to the total on-board memory size is, there you have it -- expansion. Having those extra slots on the motherboard is one example of expansion and being expandable.
When it comes to technology, support is an important thing to consider. For the most part, you will not have to worry about troubleshooting components in your Deep Learning machine. If something goes wrong then it will be repaired by an authorized technician, or replaced. The type of support relevant to the task at hand is related to usability. Essentially, you want to use components that are well supported by the manufacturer.
A good example of this are GPUs, where NVIDIA GPUs are more widely supported than those by other manufacturers. This leads to more developers writing better libraries and applications, ultimately making NVIDIA a better choice for your Deep Learning system.
While some enthusiasts recommend purchasing components separately, over time, this is not the type of advice that best suits everybody. An important factor that some overlook is the total time it takes, from start to completion, to build your system. Proponents of this strategy suggest watching the marketplace for sales, or otherwise good deals, on specific parts and purchasing them at the right time. There are at least two closely related problems with this plan.
The first is that you may not be able to test the individual components as they arrive because they are interdependent. In a perfect world, everything that you purchase will work perfectly out of the box. However, most of us know from experience that dead-on-arrival (DOA) parts arrive often enough that testing within the DOA period is important. In particular, with “open box” or refurbished parts, making sure that they function correctly is critical. The problem is that if there are too few parts to create even a barebones system then testing an individual component requires the use of a second, working system. If you don’t have one, or at least have access to one, then the new arrival has to sit on the shelf until you’re ready for it.
The second problem follows directly from the first, and it concerns the general warranty. Assuming that you are able to test the new component are verify that it’s functioning to specification, if it doesn’t have a permanent home then again, it sits on the shelf. This may not seem like a problem for something like a brand new NVIDIA Video Card with a three-year warranty, but for clearance or “open box” items, it may very well be relevant.
The bottom line is that length of time from the purchase of the first component, up until the system is built and tested, matters. In an extreme example, you don’t want several components to be out of warranty before they are even turned on.
Interested in your own pre-built deep learning system? Our Exxact Valence Workstation offers everything you need to get started to accelerate your deep learning training. Experience the power of NVIDIA GPUs, featuring selections from the RTX 2080 Ti, TITAN RTX, Quadro RTX 6000, and more. Also pre-installed with the latest deep learning frameworks including TensorFlow, PyTorch, Keras, and more!
Keeping in mind the various aspect listed above, it is now time to put some thought into the components, themselves.
The motherboard is the first option in this list because everything else plugs into it. However, it might more appropriately be placed at the end because it has to be the one piece that is compatible with everything else.
Your choice of motherboard is directly tied to which components are compatible with your system, and more importantly, how scalable, or expandable it is. Motherboards come in different form factors, where a smaller size might be easier to fit on your desk, but a lot less expandable than a larger one (e.g. MBD-C7B75-B vs MBD-X10DAC-B).
Your choice of motherboard will set the upper limit for the number of CPUs, GPUs, available memory slots, maximum supported memory, and PCI Express expansion slots. Similarly, different motherboards are only compatible with certain components such as specific CPUs and types of memory modules.
Once your motherboard has been chosen, the number of options narrows. If it is the first component that you choose then be sure to check for compatibility at each step of the way
The Graphics Processing Unit is the heart of every Deep Learning system. Regardless of the problem you’re tackling, your choice of GPU type and configuration drive the speed of your work. The first decision is the number of GPUs.
Trivially, a single-GPU system is a more cost-effective solution, and perhaps suitable for somebody who is not fully committed. Moving beyond this, a dual-GPU or multi-GPU system will allow you to run many different problems, or perhaps the same problem with many different hyper-parameter settings, in parallel. For a machine learning researcher, the ability to run experiments in parallel makes the multi-GPU system a wise investment.
Once the number of GPUs is set, the brand and model are the next things to be considered. Largely, your choice of GPU will come down to price and support. For the heart of your system, you want the best GPU that fits within your budget, with the maximum usability of third-party libraries and applications.
List of NVIDIA Turing GPUs we recommend for a deep learning system:
In the link above, we compared the 4 different types of GPUs and how they stack up for specific deep learning applications, Computer Vision and Natural Language Processing (NLP). Consider the following GPUs for NLP, where modern architectures require a large GPU memory pool to achieve best results.
BLEU Score (NLP Metric)
Here we compare training the official Transformer model (BASE and BIG) from the official TensorFlow GitHub.
| Transformer BLEU Score trained with RTX 6000 (BIG Model) | Transformer BLEU Score trained with RTX 2080 ti (BASE Model) |
| The Big model trained using the RTX 6000 can obtain a higher bleu score (based on vanilla settings for transformer model). Default settings/batch size were used on 2x RTX 6000 wNVLink system. | Here, the BASE model trained using the RTX 2080 Ti (based on vanilla settings for transformer model) clearly is inferior. Note: BIG model failed training on 2x 2080 Ti System with default batch size. |
|
| |
The Central Processing Unit may not be the computational workhorse in a Deep Learning system, but its role is important nonetheless. The job of the CPU in this situation is to handle data transport. Whether your data resides in memory or in external storage, it needs to be retrieved and supplied to the GPU. Then once the GPU has completed the necessary calculations, the results have to be moved to memory and perhaps, a hard drive or solid-state drive. If the storage is across a network, then the CPU will be responsible for communicating with the network components to supply data to and from the GPU. Essentially, it handles everything except the specific calculations that the GPU is very good at.
With myriad CPU choices, how do you know what best fits your requirements? As already mentioned, if the choice of motherboard has been made then it narrows the options. Even so, there will be factors such as clock rate, the number of PCIe lanes, and the number of cores that need to be considered.
Clock Rate
Generally speaking, the clock rate refers to how fast the CPU operates, and in a single-core CPU it is directly related to the number of instructions it can perform per second. The clock rate is not as useful for comparing CPUs from different manufacturers, but it is a common measure regardless. The next thing to consider is the maximum number of PCIe lanes.
PCIe Lanes
While the CPU is responsible for supplying data to the GPU for processing, a PCIe lane is the method of transport. The number of PCIe lanes is dependent on both the motherboard and the CPU. Often, technicians will refer to the motherboard chipset, which will have support for a maximum number of PCIe lanes. The demand, however, comes from the number of GPUs. In theory, there is a potential bottleneck in data transport unless there are 16 PCIe lines per GPU in your system.
Number of cores
In a multi-core CPU, each core can handle additional operations being executed in parallel, thus increasing the total number of instructions per second. The real question is whether this is relevant to a Deep Learning system. The answer is yes, it is.
The CPU handles the data processing in parallel with the GPU performing its own tasks. When the GPU finishes it becomes idle until the next block of data arrives, and you’ll want to minimize that downtime as much as practical. A good rule of thumb is to have two cores per GPU, so a dual-GPU system should be supported by a CPU with four cores.
When it comes to memory there are a few things to consider. The total amount of memory will dictate how much data you can load at one time. For building models, the more training data that can fit into memory, the better. Having to retrieve data from external storage is significantly slower, so for cases with lots of data, you want lots of RAM to avoid unnecessary disk accesses. At a minimum, you want to have at least as much memory in the system as there is with the largest GPU, otherwise, a potential bottleneck arises. This means that if your GPU has 32 GB then the minimum RAM you should have is 32 GB.
The form factor should also be considered, in conjunction with the number of memory slots on the motherboard, to help plan for expansion. For example, in the aforementioned 32 GB example, it would be more scalable to use two 16 GB memory modules compared to four 8 GB modules because it leaves two open slots for future expansion.
With respect to the RAM speed, the higher the better. Again, a rise in cost is typical as the speed of memory increases, so your budget will be affected accordingly.
Storage for your Deep Learning system comes in two varieties: Hard drives (HDDs) and Solid-state drives (SSDs). The traditional HDD is a cheaper, albeit slower, storage facility than an SSD. Current day systems use a combination of storage devices, with an SSD to host the operating system and frequently used files, and the HDD to store the bulk of user data and applications. A similar approach can be used for your Deep Learning system, with the SSD also being used to store active training sets.
When it comes to pricing for storage, there is always an optimal purchase point where you get the best bang for the buck. Beyond a certain threshold, you are paying far too much for a resource that is easily upgraded at a later point. Pricing for storage changes frequently, so rather than make specific suggestions, it is better to specify the minimum requirements. Budget permitting, an SSD that is between 128 GB and 256 GB is a reasonable size for the operating system and active datasets, whereas a 2 TB HDD has plenty of room for applications, a development environment, datasets, models, results, and reports.
On the topic of scalability, motherboards generally have support for several storage devices, but again, this is an option. Look for things like the number of SATA interfaces, and even the number of USB interfaces for supporting storage devices outside of the case.
Computer Power Supply Units are used to convert power from the outlet into power that is usable by the components inside the case. PSUs are rated by their wattage, so when people talk about having a bigger power supply, it normally refers to one that supplies a higher number of watts. Your choice of power supply depends on the combination of your components, being careful to leave room for expansion in the future. It is a good practice to buy one that is slightly larger than required because the only downside to having a larger PSU is the initial cost.
The Outervision Power Supply Calculator is a useful resource to help determine what size of PSU you need. There are other considerations, such as how energy efficient or noisy they are, but these options are not as important as having the power required to run your system.
Having your own Deep Learning system is a great investment that will serve your projects well, and save you money in the long run. As with any investment, there are various things to consider, and the total cost is not the least of them. Once the initial planning is complete, it is time to select the components.
Purchasing all of the necessary parts can be done at one time, or it can be spread out to make the experience more budget-friendly. However, be wary of warranties and the possibility of faulty parts that could remain untested during the construction phase.
There are numerous options for each of the critical components. Some of these are dependent on the others, so double-checking for compatibility at every step of the way is highly recommended. Similarly, the complete system should consist of parts that best suit your needs, and the requirements of the projects that you want to tackle. This means being mindful of well-supported products that have a proven record of getting work done.
Ideally, once your system is built and you’ve given it some large tasks leading to great results, it’s flexible enough to upgrade and expand to the next level.



